
Why OS
-
three core concepts:
- virtualization
- concurrency
- persistence
-
All problems in computer science can be solved by another level of indirection.
-
process -- an instance of a program
#include<std.h>
#include<unistd.h>
static int global = 0;
int main(void){
int local = 0;
while(1){
++local;
++global;
sleep(1);
}
}- In the code above, if two instances of the program are running (two processes), the addresses of
localare not the same, while addr ofglobalare the same. --- which is due to virtualization staticsimply means that the variable cannot be used outside the.cfile.
- In the code above, if two instances of the program are running (two processes), the addresses of
-
-
File Magic Numbers,
DEL E L F-> ELF (Executable and Linkable Format) file formatFile magic numbers are unique sequences of bytes at the beginning of a file that are used to identify the format of the file. These bytes are not usually visible to the user but can be used by software to determine the type of file, even if the file extension has been changed. This method is particularly useful in file forensics, software development, and systems that manage or inspect files at a binary level.
Here are some common file magic numbers and their associated file types:
-
JPEG (Joint Photographic Experts Group) images: The magic numbers for JPEG files are
FF D8 FF. JPEG files usually start with these bytes. -
PNG (Portable Network Graphics) images: PNG files start with
89 50 4E 47 0D 0A 1A 0A. -
GIF (Graphics Interchange Format) images: GIF files have
47 49 46 38as their magic numbers, followed by37 61(GIF87a) or39 61(GIF89a). -
PDF (Portable Document Format): PDF files begin with
25 50 44 46. -
ZIP files: ZIP files use
50 4B 03 04or50 4B 05 06or50 4B 07 08as their magic numbers, indicating different kinds of zip archives. -
ELF (Executable and Linkable Format) files: Used in Unix and Unix-like systems for executables, object code, shared libraries, and core dumps, with magic numbers
7F 45 4C 46. -
Microsoft Office documents:
- DOC (Word Document): Older DOC files often start with
D0 CF 11 E0 A1 B1 1A E1, identifying them as part of the Compound File Binary Format, also known as OLE (Object Linking and Embedding) or Compound Document Format. - DOCX (Office Open XML Word Document): DOCX files, along with XLSX (Excel) and PPTX (PowerPoint), are essentially ZIP files and start with the ZIP file magic numbers. They contain XML and other data files representing the document.
- DOC (Word Document): Older DOC files often start with
File magic numbers are a direct way to inspect the type of a file but require access to the file's binary content to read these initial bytes. Tools like the
filecommand in Unix/Linux use these magic numbers (among other strategies) to determine file types. -
Kernels
-
Instruction Set Architecture: three major ISAs in use today
- x86-64 (aka amd64) -- for desktops, non-Apple laptops, servers
- aarch64 (aka arm64) -- for phones, tablets, Apple laptops
- riscv (aka rv64gc) -- open source implementation, similar to ARM (pronounce: risk-five)
-
ISA: lowest level that CPU understands
-
IPC: inter-process communication is transferring data between two processes
-
File Descriptor: a resource that users may either read bytes from or write bytes to (identified by an index stored in a process) (it could represent a file, or your terminal)
-
system calls
-
we can represent system calls like regular C functions
-
two system calls needed for a basic
hello worldprogramssize_t write(inf fd, const void *buf, size_t count);write bytes from a byte array to a fdvoid exit_group(int status);exits the current process and sets an exit status code(range [0, 255],0means no errors)
-
by convention, file descriptors:
0-- standard input(read)1-- standard output(write)2-- standard error(write)
void _start(void){
write(1, "hello world\n", 12);
exit_group(0);
} -
API: Application Programming Interface (abstract a function)
-
ABI: Application Binary Interface (specifies a function in machine code)
-
System call ABI for Linux AArch64
-
svc-- generate an interrupt -
system calls use registers, while C is stack based
-
arguments pushed on the stack from right-to-left order
-
rax,rcx,rdxare caller saved -
remaining registers are callee saved
-
some arguments may be passed in registers instead of the stack
-
-
-
programs on Linux use the ELF file format
-
For the executable file:
- file header 64 bytes
- program header 56 bytes
- 120 bytes total -- above two
- instructions -- next 36 bytes
- string
Hello World\nis the next 12 bytes - so if we load the file into memory at addr 0x10000
- instructions start at 0x10078(0x78 is 120)
- data(the string) starts at 0x1009C(0x9C is 156)
readelf -a <FILE>- on MacOS
otool -tv your_program - oneline disassembler https://shell-storm.org/online/Online-Assembler-and-Disassembler/
-
Kernel Mode: a privilege level on CPU that gives access to more instructions
-
different architectures have different name for this mode -- eg. S-mode on RISC_V
-
Kernel is part of OS that runs in kernel mode
CPU MODE Software Privileged U-mode(User) Applications, libraries Least priviledged S-mode(Supervisor) Kernel H-mode(Hypervisor) Virtual machines M-mode(Machine) Bootloader, firmware Most priviledged -
straceis a command-line tool used on Linux and Unix-like operating systems to trace system calls made and received by a processstrace ./hello-worldorstrace python3 hello.pyorstrace node hello.js -
on macOS, strace is not available because macOS is based on BSD, not Linux, so use
sudo dtruss <command>instead-
from the results of
straceof different languages printing hello-world, we could see that there are space for improvement for all of the languages$ wc -l *strace.txt
71 cpp_strace.txt
702 js_strace.txt
470 py_strace.txt
-
-
The
writesystem call has a return value,printfin C also returns the number of bytes that actually printed so that you could check for errors -
think of the Kernel as a long running process
- writing kernel code is more like writing library code (there's no main)
- the Kernel lets you load code(called modules)
- your code executes on-demand
- if you write a kernel module, you can execute privileged instructions and access any kernel data
-
monolithic kernel
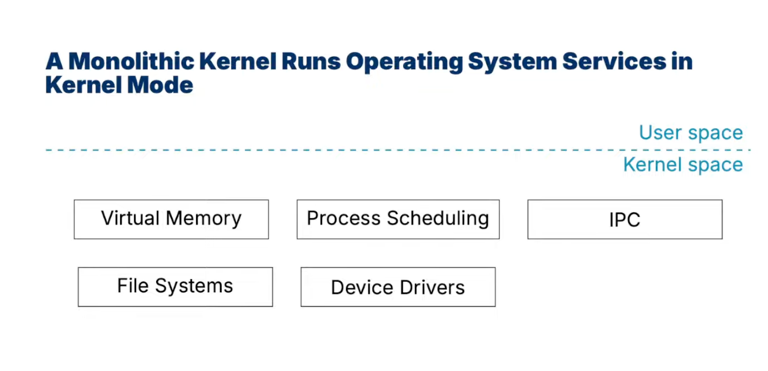
-
micro kernel

-
other types of kernel

-
the less code in the Kernel, the less likely you'll have a bug
-
in summary:
- The kernel is the part of the OS that interacts with hardware
- System calls are the interface between user and kernel mode
- file format and instructions to define a simple
hello world - ABI and API
- explore system calls with
strace - different kernel architectures shift how much code runs in kernel mode
Libraries
-
An OS consists of a kernel and libraries required for applications.
-
An OS provides the foundation for libraries.
-
normal compilation in C
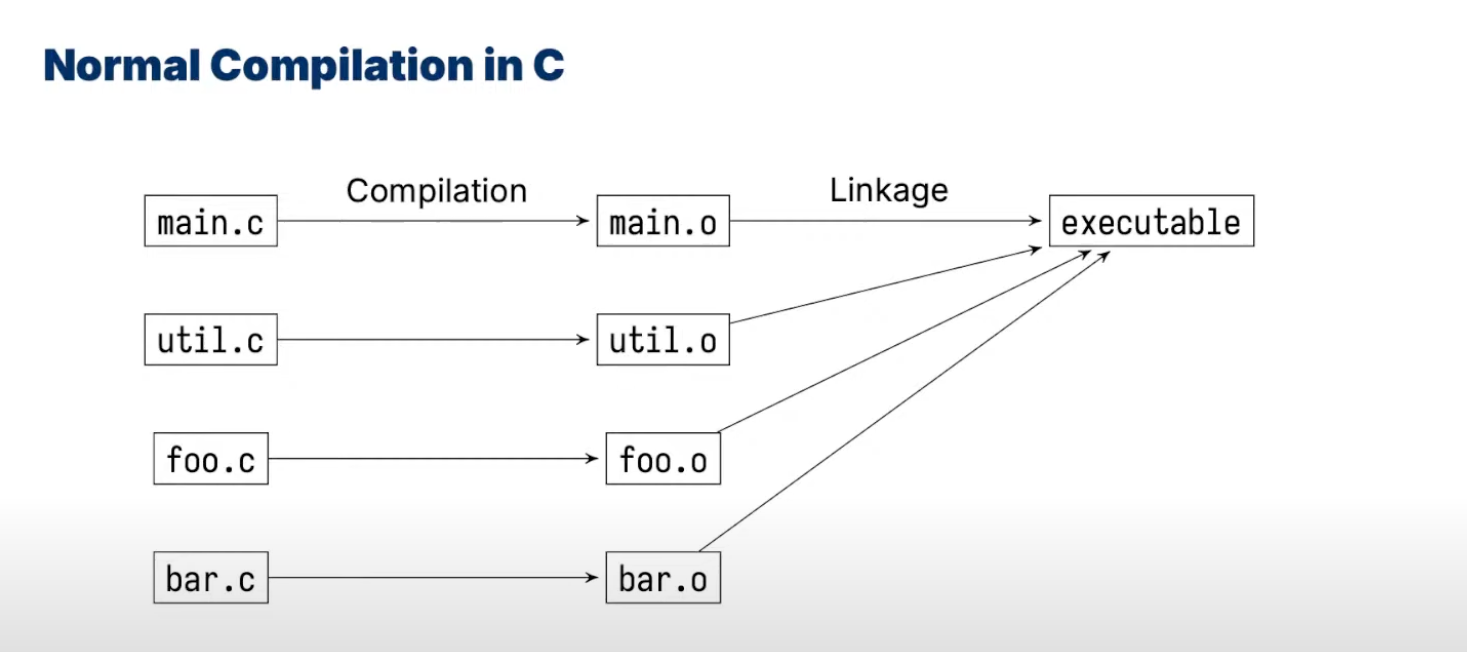
-
object files (
.o) are just ELF files with code for functions -
static libraries are included at link time
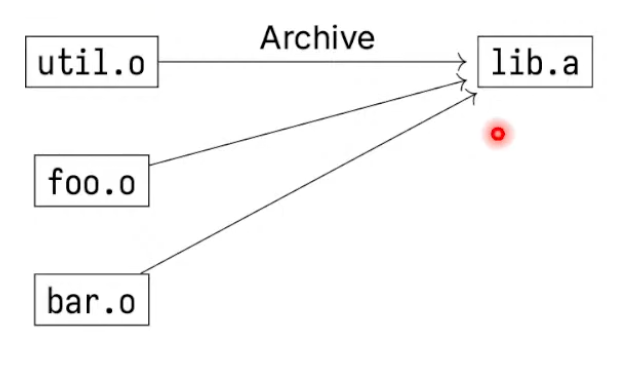
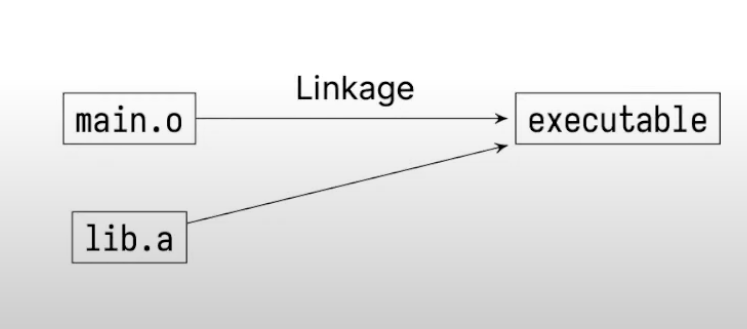
Every executable file using static libraries needs to copy those libraries, which is a bit wasteful.
-
dynamic libraries are for reusable code, they are included at runtime
- the C standard library is a dynamic library(
.so), like any other on the system - basically a collection of
.ofiles containing function definitions - multiple apps can use the same library:
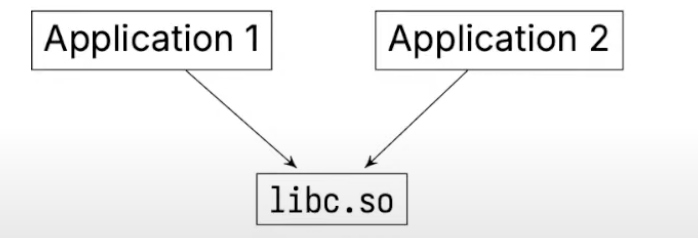
- OS only loads
libc.soin memory once, and shares it .sois short forshared object- it exists on your system and any application can use it without actually copying and pasting that code into the executable.
- In computing, a dynamic linker is the part of an operating system that loads and links the shared libraries needed by an executable when it is executed (at "run time"), by copying the content of libraries from persistent storage to RAM, filling jump tables and relocating pointers.
ldd <exectable>shows which dynamic libraries an executable uses
- the C standard library is a dynamic library(
-
drawbacks of using static libraries:
- statically linking prevents re-using lib
- any updates to a static library requires the executable to be recompiled
-
drawbacks of using dynamic libraries:
- easy to get updates, but easy to cause a crash if the update changes the ABI
- even the ABI does not change, it is still possible to cause a crash

- a proper stable ABI would hide the
structfrompoint.h LD_LIBRARY_PATHcan set which library to use
-
Semantic Versioning https://semver.org/
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API/ABI changes
MINOR version when you add functionality in a backward compatible manner
PATCH version when you make backward compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
-
control dynamic linking with environment variables
LD_LIBRARY_PATHandLLD_PRELOAD -
printfalso needs memory allocation(calls system callwritewithfd=1), and it does not free its memory in a process, butvalgrindtakes it as being freed automatically, as you don't know when you'll use it again inlibc.soand you don't know when to free it, and if the program ends, it will also be freed. -
detect memory leaks:
valgrindorAddressSanitizerAdd the
Db_sanitize=addressflag to Mesonrm -rf build
meson setup build -Db_sanitize=address
meson compile -C build -
system calls are rare in C, mostly using func from the C standard library instead
-
Most system calls have corresponding function calls in C, but may:
-
Set
errno -
Buffer reads and writes (reduce the number of system calls)
-
Simplify interfaces(function combines two system calls)
-
Add new features eg. C
exithas a feature to register functions to call on programexit(atexit), while system callexitorexit_groupsimply to stop the program at that pointvoid fini(void){ puts("Do fini");}
int main(void) {
atexit(fini);
puts("Do main");
return 0; // equivalent to exit(0);
}
// outputs:
// Do main
// Do fini
-
Process Creation
-
Process: an instance of a running program
-
A Process Control Block(PCB) contains all information and each process get a unique process ID(pid) to keep track of it
- Process state
- CPU registers
- Scheduling information
- Memory management information
- I/O status information
- Any other type of accounting information
- In Linux this is
struct task_structhttps://linux-kernel-labs.github.io/refs/heads/master/lectures/processes.html
-
Process State Diagram
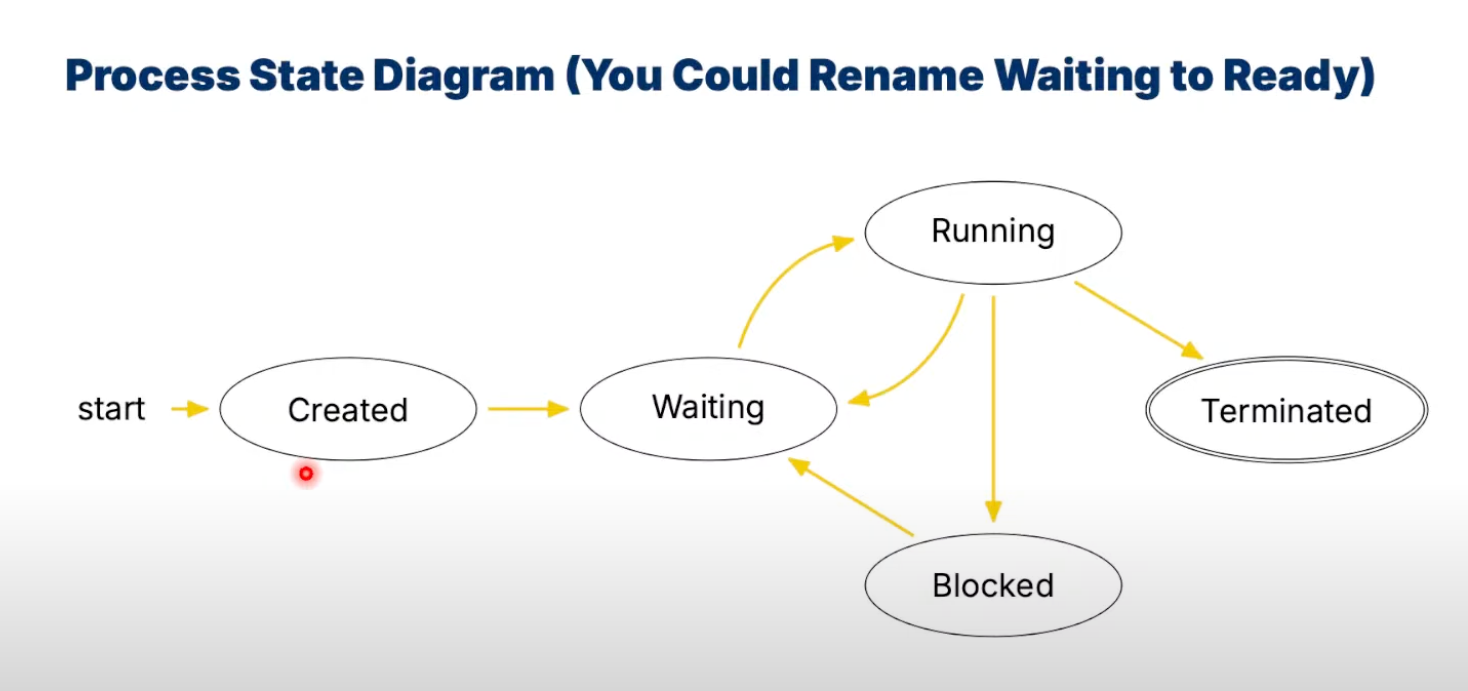
-
read process state using
procfilesystem/procdiretory on Linux represents the kernel's state (these aren't real files, they just look like it)- every directory that's a number (processID) in
/procrepresents a process - a file called
statuscontains the state - that is to say, a summary of the resources a process has can be obtain from the
/proc/<pid>directory, where<pid>is the process id for the process we want to look at. https://linux-kernel-labs.github.io/refs/heads/master/lectures/processes.html#processes-and-threads
-
fork()- returns twice
- returns
-1on failure - returns
0in the child process - returns
>0in the parent process (pid of child process) - use
copy on writeto maximize sharing
-
find docs using
man <function>orman <number> <function>(2: system calls, 3: library calls) on POSIX systems- User Commands: Executable programs or shell commands
- System Calls: Functions provided by the kernel
- Library Calls: Functions within program libraries
- Special Files: Usually devices, which are found in
/dev - File Formats and Conventions: For example,
/etc/passwd - Games: Self-explanatory
- Miscellaneous: Including macro packages and conventions, e.g.,
man(7),groff(7) - System Administration Commands: Programs to perform system administration tasks, usually only for the root user
- Kernel Routines: Kernel routines [Non standard]
Not all systems will have all sections, particularly sections 6, 7, and 9, which can be less commonly used or specific to certain Unix flavors.
-
check process status
less /proc/$pid/status -
code after
fork()will be executed twice (as there are two processes)#include <stdio.h>
#include <unistd.h>
int main(void) {
int x;
printf("%d\n", (void*) &x);
int a = fork();
printf("Hello World\n");
return 0;
}
// outputs:
// -1239041188
// Hello World
// Hello World#include <stdio.h>
#include <unistd.h>
int main(void) {
int x;
int a = fork();
printf("%d\n", (void*) &x);
printf("Hello World\n");
return 0;
}
// outputs:
// -1239041188
// Hello World
// -1239041188
// Hello World -
execvereplaces the process with another program and resetsThe
execvesystem call is a fundamental function within the UNIX and Linux operating systems used to execute a new program. It replaces the current process image with a new process image, effectively running a new program within the calling process's context. This system call is part of theexecfamily of functions, which also includesexecl,execp,execlp,execv, andexecvp, each providing different mechanisms for specifying the program to execute and its arguments.- The signature of the
execvesystem call is as follows:
#include <unistd.h>
int execve(const char *pathname, char *const argv[], char *const envp[]);-
pathname: Specifies the path to the executable file that should be run. -
argv: A null-terminated array of character pointers representing the argument list available to the new program. The first argument, by convention, should be the name of the executed program. -
envp: A null-terminated array of strings, conventionally of the formkey=value, which are passed as the environment of the new program.
-
Return Value
-
On success,
execvedoes not return because the current process image is replaced by the new program. The new program starts executing from itsmainfunction. -
On failure, it returns -1 and sets
errnoto indicate the error. The current process continues to run in this case.
- Usage
execveis often used in situations where precise control over the environment of the new program is required. Since it allows the calling process to specify the environment of the new program explicitly, it's particularly useful in implementing shell programs and process control utilities.- Example
#include <stdio.h>
#include <unistd.h>
int main() {
char *args[] = {"/bin/ls", "-l", NULL};
char *env[] = {NULL};
if (execve("/bin/ls", args, env) == -1) {
perror("execve");
return -1;
}
return 0; // This line is never reached if execve succeeds.
}This example attempts to execute the
lscommand with the-loption. If successful, the current process will be replaced by thelscommand, and thus, thereturn 0;line will never be executed. Ifexecvefails, an error message will be printed to stderr. - The signature of the
-
what happens to
while(1) {fork();}The code snippet
while(1) {fork();}is an example of a fork bomb when run in a UNIX-like or Linux operating system. This is a simple yet effective form of a Denial of Service (DoS) attack against a computer system that is capable of quickly overwhelming and crashing the system by depleting system resources, specifically the process table entries.Here's a breakdown of what happens:
fork()is a system call that creates a new process by duplicating the calling process. The new process is called the child process, and the calling process is called the parent process.- The
while(1)loop is an infinite loop that continuously executes its contents without termination.
When this code is executed, the following occurs:
- The initial process enters the infinite loop and calls
fork(), creating a new child process. - Both the parent and the newly created child process then return to the beginning of the loop and each calls
fork()again. - This results in four processes at the end of the second iteration, then eight, sixteen, and so on, doubling the number of processes with each iteration of the loop.
- This exponential growth in the number of processes continues indefinitely, or until the system limits are reached.
The consequences include:
- Rapid consumption of available CPU cycles as the operating system struggles to manage an ever-increasing number of processes.
- Depletion of the process table entries, leading to a point where no new processes can be created by any user of the system.
- Potential system instability or crash as essential system services are unable to spawn new processes.
- Exhaustion of memory resources due to the overhead of managing the burgeoning number of processes.
Modern operating systems implement safeguards against such abuses, including:
- Limiting the number of processes that a single user can create (
ulimiton UNIX/Linux). - Implementing process accounting and monitoring tools that can detect and mitigate the effects of fork bombs.
- Kernel-level protections to prevent a single user from monopolizing system resources.
Despite these protections, running such a code snippet without understanding its implications or without proper safeguards can lead to system instability and requires a system restart or intervention by an administrator to resolve.
Process Management
-
check a process state:
cat /proc/<pid>/status | grep StateRrunning and runnable (running and waiting)Sinterruptible sleep (blocked)Duninterruptible sleep (blocked)TstoppedZzombie
-
on Unix, the Kernel launches a single user process, which is called
init, which looks for it in/sbin/init-
should always be active, and responsibile for creating every other processes that run in the system
-
for Linux, it may be
systemd -
some OS create an "idle" process that the scheduler can run
-
The
initprocess is the first process started by the kernel during the booting of a computer system. It is the parent of all other processes and is responsible for initializing the system and starting user-space services and applications. Different operating systems have different mechanisms and programs for this initial process. Here's an overview of theinitprocesses across various operating systems:-
Linux
- SysV init: The traditional init system for UNIX and early Linux distributions, identified by its script-based configuration and execution of scripts stored in
/etc/init.d. - Upstart: Introduced by Ubuntu, it was designed to replace SysV init with an event-driven model that allows for faster boot times and more flexible configurations.
- systemd: The most widely adopted init system in modern Linux distributions now,
systemdis known for its parallel and aggressive service startup, dependency handling, and extensive suite of configuration options and system management commands.
- SysV init: The traditional init system for UNIX and early Linux distributions, identified by its script-based configuration and execution of scripts stored in
-
UNIX and UNIX-like Systems
- BSD init: Found in BSD systems (such as FreeBSD, OpenBSD, NetBSD), this is a traditional init system similar to SysV init but with differences in scripts and configuration files used for system startup and service management.
- launchd: Used by macOS,
launchdis a replacement for init that oversees the starting of daemons and applications, event handling, and logging. It combines the features of init, cron, at, and inetd.
-
Windows
- Wininit/Winlogon: In Windows operating systems,
Wininit.exeis responsible for setting up the system during boot, launching thelsass.exeandservices.exeprocesses.Winlogon.exeis responsible for handling the login and logout processes.
- Wininit/Winlogon: In Windows operating systems,
-
Solaris
- SMF (Service Management Facility): Introduced in Solaris 10, SMF replaces the traditional init system, providing more advanced features such as service dependency management, automatic restarts, and parallel execution of startup scripts.
-
Android
- init: Android uses its version of
init, which is responsible for setting up the system properties, mounting filesystems, and starting critical services defined ininit.rcscripts.
- init: Android uses its version of
These
initprocesses reflect the diversity of approaches taken by different operating systems to manage system startup and service management. Each has its own set of features and configurations tailored to the needs of the system it manages. -
-
-
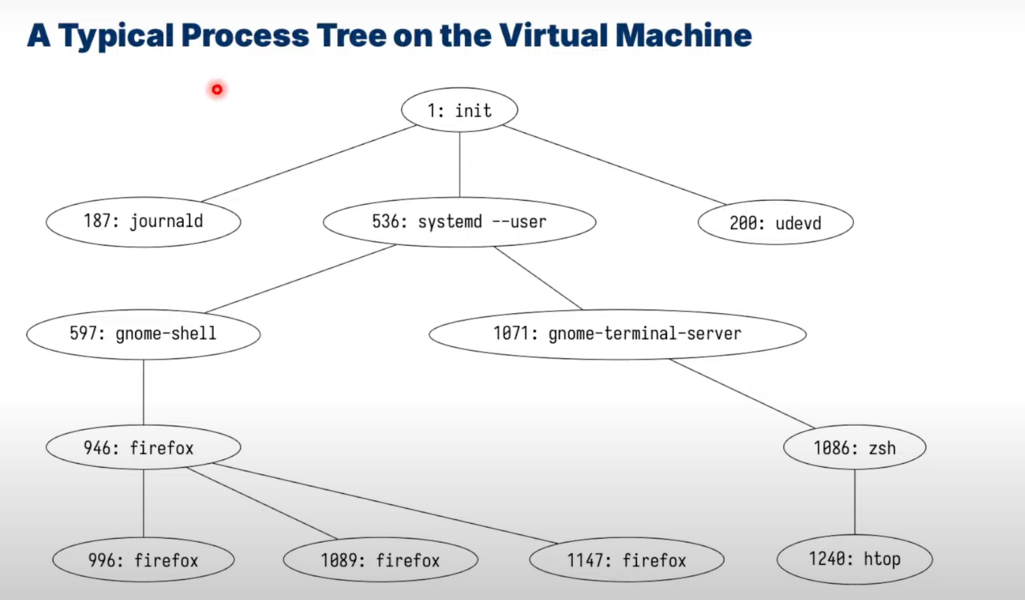
-
see the process tree
htop, pressF5to switch between tree and list view -
in an OS there are lots of processes sleeping
-
processes are assigned a Process ID on creation and does not change
pidis just a number, and is unique for every active process- on most linux systems the max pid is 32768 and 0 is reserved(invalid)
- eventually the kernel will recycle a pid, after the process dies, for a new process
- each process has its own address space(independent view of memory)
-
maintaining the Parent/Child relationship
-
what happens if the parent process exists first, and no longer exists?
-
OS sets the exit status when a process terminates(procesee terminates by calling exit), it cannot remove its PCB yet
-
two situations we may get into:
=> A. the child exits first(zombie process) (child's PCB is still there, but it actually terminated)
=> B. the parent exits first(orphan process)
-
-
-
call
waiton child process, to avoid such situations-
waitas the following API:-
status: Address to store the wait status of the process -
returns the process ID of child processes
- -1: on failure
- 0: for non-blocking calls with no child changes
- >0: the child with a change
-
the wait status contains a bunch of info, including the exit code
-
use
waitpidto wait on a specific child process
int main(void){
pid_t pid = fork();
if (pid==-1) return errno;
if (pid==0) sleep(2); // child process sleeps 2 seconds and then it exits
//parent process
// if there are multiple child processes running, it will catch the status of the first existed child process
// can only wait for the direct children
else {
printf("calling wait\n");
int wstatus;
pid_t wait_pid = wait(&wstatus);
if(WIFEXITED(wstatus)){
printf("Wait returned for an exited process! pid: %d, status: %d\n", wait_pid, WEXISTSTATUS(wstatus));
} else {
return ECHILD;
}
}
return 0;
} -
-
-
A zombie process waits for its parent to read its exit status
- the process is terminated, but it hasn't been acknowledged
- a process may have an error in it, where it never reads teh child's exit status
- OS can interrupt the parent process to acknowledge the child
- it is just a suggestion and the parent is free to ignore it
- this is a basic form of IPC called a signal
- OS has to keep a zombie process until it's acknowledged, if the parent ignores it, the zombie process needs to wait to be re-parented
-
An orphan process needs a new parent
- the child process lost its parent process
- the child still needs a process to acknowledge its exit
- OS re-parents the child process to
init, theinitprocess is now responsible to acknowledge the child - OS will also make sure that a process has a parent (except
init)
int main(int argc, char *argv[]){
pid_t pid = fork();
if (pid==-1) {
int err = errno;
perror("fork failed");
return err;
}
// child process, print and sleep 2 sec and then print again
if (pid==0) {
printf("Child parent pid: %d\n", getppid());
sleep(2);
printf("Child parent pid after sleep: %d\n", getppid());
}
// parent process: sleep one second and terminate
else {
sleep(1);
}
return 0;
}
Basic IPC
-
IPC is transferring bytes between two or more processes
- reading and writing files is a form of IPC
- the read and write system calls allow any bytes
#include <stdio.h>
#include <sys/stat.h>
#include <unistd.h>
int main(void){
char buffer[4096];
ssize_t bytes_read;
while ((bytes_read = read(0, buffer, sizeof(buffer)))>0) {
ssize_t bytes_written = write(1, buffer, bytes_read);
if (bytes_written == -1) {
int err = errno;
perror("write");
return err;
}
assert(bytes_read == bytes_written);
}
if (bytes_read == -1) {
int err = errno;
perror("read");
return err;
}
assert(bytes_read == 0);
return 0;
}add changes the code above to use on files: (freeing fd 0 and open a file instead)
int main(int argc, char *argv[]){
if (argc > 2) return EINVAL;
if (argc == 2) {
close(0); // fd
int fd = open(argv[1], O_RDONLY);
if (fd==-1){
int err = errno;
perror("open");
return err;
}
}
...
}above is also the implementation of
cat -
writejust writes data to a file descriptor, seeman 2 write -
writereturns the number of bytes written, you cannot assume it's always successful, saveerrnoif you are using another function that may set it. -
both ends of the read and write have a corresponding
writeandread, this makes two communication channels with command line programs. -
Linux uses the lowest available file descriptor for new ones
-
press
ctrl+cto stop a running program is actually sending a signalSIGINT(interrupt from keyboard) to the process. -
if the default handler occurs the exit code will be 128 + signal number
-
signals are a form of IPC that interrupts
- press CTRL+C to stop
- kernel sends a number to the program indicating the type of signal (Kernal default handlers either ignore the signal or terminate the process)
- CTRL+C sends
SIGINT
-
set your own signal handlers with
sigaction, seeman 2 sigaction- declare a function that does not return a value, and has an int arg, the int is the signal number
- some numbers are non standard, below are a few from Linux x86-64
- 2: SIGINT(interrupt from keyboard)
ctl-c - 9: SIGKILL(terminate immediately)
kill -9 xxx, it is a special signal, if you register to ignore all signals, using this command can terminate the process immediately while ctrl-c or kill xxx do not work - 11: SIGSEGV(memory access violation)
- 15: SIGTERM(terminate)
kill xxx
- 2: SIGINT(interrupt from keyboard)
-
certain keystroke combinations are configured to deliver a specific signal to the currently running process
-
control-c sends a
SIGINT(interrupt) to the process (normally terminating it) -
control-z sends a
SIGTSTP(stop) signal thus pausing the process in mid-execution(you can resume it later with a command, e.g., the fg built-in command found in many shells) -
signal()can catch various signals, doing so ensures that when a particular signal is delivered to a process, it will suspend its normal execution and run a particular piece of code in response to the signal.Registering a signal in C is a common practice for handling asynchronous events, such as interrupts from the keyboard, timers, or other system events. The
signal()function from the C Standard Library (specifically,<signal.h>) is used to set up a signal handler. Below is a simple example of how to register a signal handler for the SIGINT signal, which is typically sent when the user presses Ctrl+C in the terminal.#include <stdio.h>
#include <signal.h>
#include <unistd.h>
// Signal handler function
void signal_handler(int signal) {
printf("Caught signal %d\n", signal);
// Perform any cleanup or necessary operations here
// Optionally, restore default behavior and raise the signal again
// signal(signal, SIG_DFL);
// raise(signal);
}
int main() {
// Register signal handler for SIGINT
if (signal(SIGINT, signal_handler) == SIG_ERR) {
printf("Can't catch SIGINT\n");
}
// Main loop to keep the program running and able to receive the signal
while(1) {
printf("Waiting for SIGINT (Ctrl+C)...\n");
sleep(1); // Sleep for 1 second
}
return 0;
}In this example, the
signal_handlerfunction is defined to handle signals. It simply prints the signal number when caught. Thesignal()function is used to registersignal_handleras the handler for SIGINT signals. Inside the main loop, the program prints a message and then sleeps for one second, repeating indefinitely. This keeps the program running so that it can receive and respond to signals.Note that using
signal()is considered less reliable and portable thansigaction()for complex signal handling, especially in multithreaded programs. However, for simple cases or programs that are not multithreaded,signal()is often sufficient. -
send signals with
pid- using
pidof xxxto get the process id kill <pid>by default sendsSIGTERMkill -9 <pid>to terminate the process immediately, but process won't terminate if it's in uninterruptible sleep
- using
-
most operations are non-blocking
- a non-blocking call returns immediately and you can check if something occurs
- to turn
waitinto a non-blocking call, usewaitpidwithWNOHANGin options - to react to changes to a non-blocking call, we can either use a poll or interrupt
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
pid_t pid;
int status;
// Fork a child process
pid = fork();
if (pid == -1) {
// Error
perror("fork");
return EXIT_FAILURE;
} else if (pid == 0) {
// Child process
printf("Child process (PID: %d)\n", getpid());
// Simulate some work by sleeping
sleep(2);
exit(EXIT_SUCCESS);
} else {
// Parent process
printf("Parent process (PID: %d), waiting for child (PID: %d)\n", getpid(), pid);
while (1) {
// Non-blocking wait
pid_t result = waitpid(pid, &status, WNOHANG);
if (result == 0) {
// Child is still running
printf("Child (PID: %d) is still running. Checking again...\n", pid);
sleep(1); // Sleep for a bit before checking again
} else if (result == -1) {
// Error occurred
perror("waitpid");
break;
} else {
// Child has exited
if (WIFEXITED(status)) {
printf("Child (PID: %d) exited with status %d\n", pid, WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Child (PID: %d) was terminated by signal %d\n", pid, WTERMSIG(status));
}
break; // Exit the loop
}
}
}
return EXIT_SUCCESS;
} -
SIGCHLDis a signal used in UNIX and UNIX-like operating systems to indicate to a parent process that one of its child processes has stopped or exited, or that a child process has been terminated due to a signal that was not caught.
-
Purpose: The primary purpose of SIGCHLD is for a parent process to be notified of changes in the status of its child processes. It allows the parent process to perform necessary actions, such as cleaning up resources used by the child process (this is often done by calling wait() or waitpid() in the signal handler to reap the child process and retrieve its exit status).
-
Default Behavior: By default, SIGCHLD signals are ignored. This means that if a parent process does not explicitly handle or block this signal, the signal's occurrence will not affect the parent process's execution.
-
Usage: A process can change the action taken by a process on receipt of a SIGCHLD signal by using the signal() or sigaction() system calls. It can set up a signal handler function that is called whenever the SIGCHLD signal is received, allowing the parent process to take appropriate actions, such as reaping zombie processes (child processes that have terminated but still have an entry in the process table).
-
Zombie Processes: If a child process terminates and the parent process does not immediately collect the child's exit status by calling wait() or waitpid(), the child process remains in a "zombie" state. Handling SIGCHLD allows the parent process to clean up these zombie states efficiently.
-
Below is a simple C example that demonstrates how to handle the
SIGCHLDsignal. This example involves creating a child process usingfork(). The parent process sets up a signal handler forSIGCHLDto catch when the child process exits. Upon receivingSIGCHLD, the parent process will then reap the child process usingwaitpid(), thus cleaning up the zombie process.#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <signal.h>
// Signal handler for SIGCHLD
void sigchld_handler(int sig) {
// Temporary storage for the child's status
int status;
// PID of the terminated child
pid_t child_pid;
// Wait for all children that have terminated, non-blocking call
while ((child_pid = waitpid(-1, &status, WNOHANG)) > 0) {
if (WIFEXITED(status)) {
printf("Child %d exited with status %d\n", child_pid, WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Child %d was killed by signal %d\n", child_pid, WTERMSIG(status));
}
}
}
int main() {
pid_t pid;
// Set up the signal handler for SIGCHLD
struct sigaction sa;
sa.sa_handler = sigchld_handler; // Set the handler function
sigemptyset(&sa.sa_mask); // Initialize the signal set to empty
sa.sa_flags = SA_RESTART | SA_NOCLDSTOP; // Restart functions if interrupted by handler
if (sigaction(SIGCHLD, &sa, NULL) == -1) {
perror("sigaction");
return EXIT_FAILURE;
}
// Create a child process
pid = fork();
if (pid == -1) {
// Error occurred
perror("fork");
return EXIT_FAILURE;
} else if (pid == 0) {
// Child process
printf("Child process (PID: %d)\n", getpid());
// Simulate some work in the child process
sleep(2);
printf("Child process (PID: %d) completing\n", getpid());
exit(0); // Exit normally
} else {
// Parent process
printf("Parent process (PID: %d), waiting for child (PID: %d) to complete\n", getpid(), pid);
// Do some work in the parent process; the actual wait is handled in sigchld_handler
for (int i = 0; i < 5; ++i) {
printf("Parent working...\n");
sleep(1);
}
}
return EXIT_SUCCESS;
}
In this example:
-
The
sigchld_handlerfunction is defined to handleSIGCHLDsignals. It useswaitpidwith theWNOHANGoption to reap any child processes that have exited, without blocking if there are no children that have exited. -
The
sigactionsystem call is used to set up thesigchld_handleras the handler forSIGCHLD. This is more robust and flexible than usingsignal(), particularly because it allows for specifying flags such asSA_RESTART, which makes certain system calls restartable after a signal is handled. -
The parent process creates a child process using
fork(). The child process simulates doing some work by sleeping for 2 seconds before exiting. -
The parent process itself does some work in a loop, demonstrating that it continues to run and is not blocked waiting for the child process to exit. The clean-up of the child process is managed asynchronously through the signal handler.
- it's ok to have an orphan process but should avoid having a zombie process
The wait(NULL) function call in C, used within a process running on a Unix-like operating system, is a system call that blocks the calling process until one of its child processes exits or a signal is received. When a child process exits, the wait function collects the process's termination status and cleans up the resources used by the child process, preventing it from becoming a zombie process.
Here's a breakdown of the wait(NULL) function call:
-
wait(): This function is part of the C standard library and is included via the<sys/wait.h>header file. It is used for process synchronization and resource management. -
NULL: The argument passed towait()in this case isNULL. This indicates that the caller is not interested in the exit status of the child process. If the caller does care about the exit status, a pointer to an integer variable should be passed instead, andwait()will store the status information in that variable, allowing the caller to analyze the child's exit reason (normal exit, signal termination, etc.).
- The primary purpose of
wait(NULL)is to wait for the child processes to change state. It is commonly used in programs where the parent process forks a child process and then needs to wait for the child process to complete its execution before proceeding. This ensures that resources are properly managed and that the parent can perform necessary actions after the child has exited, such as continuing with its own execution flow, creating more child processes, or cleaning up.
If a process has no child processes, calling wait(NULL) will return immediately with an error. If the process has multiple child processes, wait(NULL) will return when any one of them exits, and subsequent calls can wait for additional children to exit.
Example usage in a simple program:
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid == -1) {
// Fork failed
perror("fork");
return EXIT_FAILURE;
} else if (pid == 0) {
// Child process
printf("Child process: PID=%d\n", getpid());
sleep(2); // Simulate some operation
exit(EXIT_SUCCESS);
} else {
// Parent process
printf("Parent process: PID=%d, waiting for child PID=%d\n", getpid(), pid);
wait(NULL); // Wait for the child to exit
printf("Child process has exited. Parent process resuming.\n");
}
return EXIT_SUCCESS;
}
In this example, the parent process forks a child process, waits for it to exit using wait(NULL), and then resumes its execution after the child process has terminated.
-
The command
kill -9 -1is a powerful and potentially dangerous UNIX/Linux command when executed with superuser (root) privileges. It sends the SIGKILL signal (-9) to all processes that the current user is allowed to send signals to, except for the init process (PID 1). The -1 specifies that the signal should be sent to all such processes. -
On modern Ubuntu systems, which typically use systemd as the init system, attempting to run
sudo kill -9 1to send the SIGKILL signal to process with PID 1 (which is systemd) will not terminate the init process. systemd is designed to ignore SIGKILL signals, so this command will not have the intended effect of stopping the init system. This design is a safety feature to prevent accidental or malicious attempts to bring down the system by killing essential system services managed by systemd. -
The
sigactionsystem call in Unix-like operating systems is used to examine and change the action associated with a specific signal. Unlike the simplersignalfunction,sigactionprovides more extensive control over signal handling, including the ability to block other signals while a signal handler is executing and to specify flags that control the behavior of the signal handling.
The sigaction structure and function call allow a process to define how it should handle signals, whether by ignoring them, catching them with a user-defined function, or restoring the default behavior.
Structure of sigaction
The sigaction structure is defined in the <signal.h> header file and typically looks like this:
struct sigaction {
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};
sa_handler: This specifies the action to be associated with the specified signal. It can beSIG_DFL(default action),SIG_IGN(ignore the signal), or a pointer to a signal handling function.sa_sigaction: This is an alternative tosa_handler, used whenSA_SIGINFOis specified insa_flags. It provides a signal handling function that can accept additional information about the signal.sa_mask: Specifies a set of signals that should be blocked during the execution of the signal handling function. These signals are added to the process's signal mask before the handler is executed and removed afterward.sa_flags: This can be used to modify the behavior of the signal. Flags includeSA_RESTART(to make certain interrupted system calls restartable),SA_SIGINFO(to use thesa_sigactionfield instead ofsa_handler), among others.sa_restorer: This is not used in modern implementations and is often omitted.
Here is an example of how to use sigaction to set a custom handler for the SIGINT signal (generated by pressing Ctrl+C in the terminal):
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
void sigint_handler(int signum) {
// Custom action for SIGINT
printf("Caught SIGINT (%d)\n", signum);
}
int main(void) {
struct sigaction act;
act.sa_handler = sigint_handler;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
if (sigaction(SIGINT, &act, NULL) < 0) {
perror("sigaction");
return 1;
}
// Loop to keep the program running so it can catch SIGINT
while (1) {
printf("Sleeping for 2 seconds...\n");
sleep(2);
}
return 0;
}
In this example, sigaction is used to set sigint_handler as the handler for SIGINT. The sa_mask is initialized to block no additional signals during the execution of the handler, and sa_flags is set to 0, indicating no special behavior.
The sigaction system call provides a robust and flexible way to handle signals, making it the preferred choice for complex applications and systems programming.
cat /proc/self/statuschecks the status of the process that reads/proc/self/status
~ cat /proc/self/status
Name: cat
Umask: 0002
State: R (running)
Tgid: 2043874
Ngid: 0
Pid: 2043874
PPid: 2043839
TracerPid: 0
Uid: 1000 1000 1000 1000
Gid: 1000 1000 1000 1000
FDSize: 64
Groups: 27 1000
NStgid: 2043874
NSpid: 2043874
NSpgid: 2043874
NSsid: 2043839
VmPeak: 6176 kB
VmSize: 6176 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 1012 kB
VmRSS: 1012 kB
RssAnon: 88 kB
RssFile: 924 kB
RssShmem: 0 kB
VmData: 360 kB
VmStk: 132 kB
VmExe: 16 kB
VmLib: 1680 kB
VmPTE: 44 kB
VmSwap: 0 kB
HugetlbPages: 0 kB
CoreDumping: 0
THP_enabled: 1
Threads: 1
SigQ: 0/3670
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000000
SigCgt: 0000000000000000
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: 000001ffffffffff
CapAmb: 0000000000000000
NoNewPrivs: 0
Seccomp: 0
Seccomp_filters: 0
Speculation_Store_Bypass: vulnerable
SpeculationIndirectBranch: conditional enabled
Cpus_allowed: 1
Cpus_allowed_list: 0
Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001
Mems_allowed_list: 0
voluntary_ctxt_switches: 0
nonvoluntary_ctxt_switches: 1
-
The
/proc/self/statusfile is part of the proc filesystem (procfs), which is a pseudo-filesystem used by Linux and other Unix-like operating systems to provide an interface to internal data structures. It doesn't contain real files but runtime system information (e.g., system memory, devices mounted, hardware configuration, etc.). -
When a process reads from
/proc/self/status, it gets information about itself. The self symlink points to the process accessing the/procdirectory, making it a convenient way to get process-specific information without knowing the process ID.- Name: The name of the command that ran the process.
- Umask: The process's file mode creation mask.
- State: The state of the process (e.g., running, sleeping, zombie).
- Tgid: Thread group ID (the PID of the leader of the group to which this process belongs).
- Ngid: Numerical group ID of the process.
- Pid, PPid, TracerPid: The PID of the process, its parent's PID, and the PID of the tracer process if the process is being traced.
- Uid, Gid: Real, effective, saved set, and filesystem UIDs and GIDs.
- FDSize: Number of file descriptor slots currently allocated.
- Groups: Supplementary group list.
- VmPeak, VmSize, VmLck, VmPin, VmHWM, VmRSS, VmData, VmStk, VmExe, VmLib, VmPTE, VmSwap: Various details about memory usage, including peak virtual memory size, total program size, locked memory size, and others.
- Threads: Number of threads in the process.
- SigQ: Signal queue (signals pending/limit).
- SigPnd, ShdPnd: Signals pending for the thread and for the process as a whole.
- CapInh, CapPrm, CapEff, CapBnd, CapAmb: Capability sets.
- Seccomp: Seccomp mode of the process.
- Cpus_allowed, Cpus_allowed_list, Mems_allowed, Mems_allowed_list: CPUs and memory nodes allowed for the process.
- voluntary_ctxt_switches, nonvoluntary_ctxt_switches: Number of voluntary and involuntary context switches.
Process Practice
-
install xv6-riscv on macOS
brew install qemu
brew tap riscv/riscv
brew install riscv-tools
git clone https://github.com/mit-pdos/xv6-riscv.git && cd xv6-riscv
make qemu TOOLPREFIX=riscv64-unknown-elf- -
https://github.com/mit-pdos/xv6-riscv a re-implementation of Unix version 6 for RISC-V in C
-
uniprogramming is for old batch processing OSs
- uni-programming: only one process running at a time, any two processes are not parallel and not concurrent, no matter what. e.g dos
- multiprogramming: allow multi processes, modern OS try to run everything in parallel and concurrently
-
The Fork Bomb:
:(){ :|:& };: -
for true multitasking the OS can:
- give processes set time slices
- wake up periodically using interrupts to do scheduling
-
context switching: swapping processes
- at minimum save all the current registers
- pure overhead, want it to be as fast as possible
- using the combination of software and hardware to save as little as possible
-
system call is typically slow
-
pipeint pipe(int pipefd[2]);- returns 0 on success and -1 on failure (and sets errno)
pipefd[0]read end of the pipepipefd[1]write end of the pipe- read from
pipefd[0]and write topipefd[1] - can think of it as a kernel managed buffer, any data written to one end can be read on the other end
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
int pipefd[2];
pid_t cpid;
char buf;
if (pipe(pipefd) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
cpid = fork();
if (cpid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
if (cpid == 0) { /* Child reads from pipe */
close(pipefd[1]); // Close unused write end
while (read(pipefd[0], &buf, 1) > 0)
write(STDOUT_FILENO, &buf, 1);
write(STDOUT_FILENO, "\n", 1);
close(pipefd[0]);
_exit(EXIT_SUCCESS);
} else { /* Parent writes argv[1] to pipe */
close(pipefd[0]); // Close unused read end
write(pipefd[1], "Hello, world!\n", 14);
close(pipefd[1]); // Reader will see EOF
wait(NULL); // Wait for child
exit(EXIT_SUCCESS);
}
} -
Program 1
int main() {
int i = 4;
while (i != 0) {
int pid = fork();
if (pid == 0) {
i--;
}
else {
printf("%d\n", i);
exit(0);
}
}
return 0;
}
This program forks a new process in each iteration of the loop until i is decremented to 0. The child process (if (pid == 0)) decrements i and continues the loop, whereas the parent process prints the current value of i and then exits.
- Output Variability: The output of this program may vary between runs. However, due to the structure of this program where each parent process exits after printing and only the child process continues the decrementing loop, the behavior is quite deterministic. In each generation of processes,
iis decremented once before a fork happens again, leading to a sequence of prints from 4 down to 1 in different processes. However, due to how processes are scheduled by the operating system, there could be variability in the order in which these outputs appear, especially in a multitasking environment. But given the immediate exit of the parent process after printing, the program is somewhat deterministic in its behavior, as it enforces a sort of sequential order to the execution.
- Program 2
int main() {
int i = 4;
while (i != 0) {
int pid = fork();
if (pid == 0) {
i--;
} else {
waitpid(pid, NULL, 0);
printf("%d\n", i);
exit(0);
}
}
return 0;
}
This version includes a call to waitpid() in the parent process, making the parent wait for the child process to finish before continuing to print i and exit.
- Output Consistency: This program is designed to be more deterministic than the first. The
waitpid()call ensures that the child process completes its execution (which involves decrementingiand possibly forking again) before the parent proceeds to print and exit. This synchronization forces a strict parent-child execution order, which makes the output consistent across runs. The parent waits for its immediate child to complete, ensuring that the decrement and potential forking by the child are completed before the parent prints and exits. Given this structure, each level of forked process will sequentially decrementiand print its value in a controlled manner, leading to a predictable and consistent output sequence.
In summary:
- Program 1 may seem to have a deterministic output because each parent exits immediately after printing, but there's a slight chance of variability in the scheduling and execution order, making its output potentially vary in a highly concurrent or multitasking environment.
- Program 2 will produce the same output every time it is run because
waitpid()enforces a strict execution order between parent and child processes, leading to deterministic behavior and consistent output.
Subprocess
-
send and receive data from a process
- create a new process that launches the command line argument
- send the string
Testing\nto that process - receive any data it writes to standard outputs
-
execlpint execlp(const char *file, const char *arg, ... /*, (char *) NULL */);does not return on success, and -1 on failure(and sets errno)- it lets you skip using string arrays, and search for executables using the
PATHenvironment variable
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
// Attempt to execute the "ls" command, listing directory contents
if (execlp("ls", "ls", "-l", (char *)NULL) == -1) {
perror("execlp failed");
exit(EXIT_FAILURE);
}
// This line will not be executed if execlp is successful
printf("This will not be printed if 'ls' is successfully executed.\n");
return 0;
}In this example,
execlpis used to execute thelscommand with the-loption to list directory contents in long format. Ifexeclpsucceeds, theprintfstatement following it will not execute because the current process image is replaced by thelscommand. Ifexeclpfails (e.g., if the command is not found), an error message is printed usingperror, and the program exits with a failure status.using
execlpis a bit more convenient thanexecve#include <stdio.h>
#include <unistd.h>
int main() {
char *binaryPath = "/bin/ls"; // Path to the binary to execute
char *args[] = {binaryPath, "-l", NULL}; // Arguments to pass to the binary, ending with NULL
char *env[] = {NULL}; // Environment variables, ending with NULL
printf("Executing %s\n", binaryPath);
if (execve(binaryPath, args, env) == -1) {
perror("Could not execve");
}
// If execve is successful, this code is not reached.
return 0;
} -
dupanddup2-
int dup(int oldfd);andint dup2(int oldfd, int newfd); -
returns a new fd on success and -1 on failure (and sets errno)
-
copies the fd so
oldfdandnewfdrefer to the same thing -
for
dup, it returns the lowest fd -
for
dup2, it will closenewfdbeforenewfdis made to referred to the same thing asoldfd
-
-
The
dupsystem call duplicates an open file descriptor and returns a new file descriptor. The new file descriptor returned bydupis guaranteed to be the lowest-numbered file descriptor not currently in use by the process.
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
// Open a file
int fileDescriptor = open("example.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fileDescriptor < 0) {
perror("open");
return 1;
}
// Duplicate the file descriptor
int newFileDescriptor = dup(fileDescriptor);
if (newFileDescriptor < 0) {
perror("dup");
close(fileDescriptor);
return 1;
}
// Use the original and the duplicated file descriptors
write(fileDescriptor, "Hello, ", 7);
write(newFileDescriptor, "world!\n", 7);
// Close file descriptors
close(fileDescriptor);
close(newFileDescriptor);
return 0;
}
-
The
dup2system call performs a similar function todup, but it allows the caller to specify the value of the new file descriptor. If the specified file descriptor is already open,dup2will first close it before duplicating the old descriptor (unless the old and new descriptors are the same, in which casedup2does nothing).#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
// Open a file
int fileDescriptor = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fileDescriptor < 0) {
perror("open");
return 1;
}
// Redirect standard output to the file
if (dup2(fileDescriptor, STDOUT_FILENO) < 0) {
perror("dup2");
close(fileDescriptor);
return 1;
}
// Now, printf writes to the file
printf("This goes to the file 'output.txt'\n");
// Close file descriptor (standard output is still open)
close(fileDescriptor);
return 0;
} -
use cases
-
dup: Use when you need a new file descriptor and don't care about its specific value. This is common when you simply need another handle to an open file for operations like reading or writing from different positions. -
dup2: Use when you need to replace a specific file descriptor, often for redirection purposes. For example, redirecting the output of a child process in a shell program to implement features like output redirection (command > file) or piping between commands (command1 | command2).
-
-
static void parent(int in_pipefd[2], int out_pipefd[2], pid_t child_pid) {
char buffer[4096];
ssize_t bytes_read = read(out_pipefd[0], buffer, sizeof(buffer));
check_error(bytes_read, "read");
printf("Read: %.*s", (int) bytes_read, buffer); // printf will always output to file descriptor 1, no matter what fd1 is
}
static void child(int in_pipefd[2], int out_pipefd[2], const char *program){
// 0: stdin
// 1: stdout
// 2: stderr
// 3: out_pipefd[0]: read end of out_pipe
// 4: out_pipefd[1]: write end of out_pipe
check_error(dup2(in_pipefd[0], 0), "dup2");
check_error(close(in_pipefd[0]), "close");
check_error(close(in_pipefd[1]), "close");
check_error(dup2(out_pipefd[1], 1), "dup2"); // redirect output
check_error(close(out_pipefd[0]), "close");
check_error(close(out_pipefd[1]), "close");
// 0: read end of in_pipe
// 1: write end of out_pipe
// 2: stderr
printf("Debugging...\n");
fflush(NULL); // make fd1 get back to std output, instead of being write end of out_pipe
execlp(program, program, NULL);
}
int main(int argc, char *argv[]){
if (argc != 2) {return EINVAL;}
// 0: stdin
// 1: stdout
// 2: stderr
int in_pipefd[2] = {0}; // initialize the array
check_error(pipe(in_pipefd), "pipe");
int out_pipefd[2] = {0}; // initialize the array
check_error(pipe(out_pipefd), "pipe");
// 0: read end of in_pipe
// 1: stdout
// 2: stderr
// 3: out_pipefd[0]: read end of out_pipe
// 4: out_pipefd[1]: write end of out_pipe
pid_t pid = fork();
if (pid > 0) {
parent(in_pipefd, out_pipefd, pid);
} else {
child(in_pipefd, out_pipefd, argv[1]);
}
} -
The
fflushfunction in C is used to flush a stream, forcing a write of all user-space buffered data for the given output or update stream via the stream's underlying write function. When you callfflushwith a specific file stream as an argument, it flushes just that stream. However, when you callfflush(NULL);, it has a special behavior.Calling
fflush(NULL);flushes all open output streams. This means that any buffered data for any output stream (likestdout) or for update streams in which the most recent operation was not input, will be written to the respective files or devices. This can be particularly useful in situations where you want to ensure that all output buffers have been flushed without having to callfflushindividually on each open stream.This behavior is defined by the C standard (C99 and onwards), making it a portable way to flush all output streams in a program. However, it's important to note that flushing input streams using
fflushis undefined behavior according to the C standard, sofflush(NULL);is specifically about affecting output streams.Using
fflush(NULL);is common in programs where you want to ensure that all output has been physically written to the output devices or files before proceeding, such as before a program termination, or before performing an operation that might affect the program's output channels in a way that could lead to data loss if buffers were not flushed.
Basic Scheduling
-
preemptible resource -- can be taken away and is shared through scheduling, eg. a CPU
-
non-preemptible resource -- cannot be taken away without acknowledgement, eg. disk space, and is shared through allocations and deallocations
-
parallel and distributed systems may allow you to allocate a CPU
-
a dispatcher and scheduler work together:
- a dispatcher is a low-level mechanism, responsible for context switching
- a scheduler is a high-level policy, responsible for deciding which process to run
-
the scheduler runs whenever a process changes state
- for non-preemptable processes, once the process starts, it runs until completion, and the scheduler will only make a decision when the process terminates
- preemptive allows OS to run the scheduler at will,
uname -vcan tell you whether the kernel is preemptable
-
Metrics
- minimize waiting time and response time -- don't have a process waiting too long or too long to start
- maximize CPU utilization -- don't have the CPU idle
- maximize throughput -- complete as many processes as possible
- fairness -- try to give each process the same percentage of the CPU
-
Scheduling
-
First-Come First-Served -- most basic, no preemption
-
Shortest Job First -- no preemption, reduce avg waiting time than FCFS
- but it is not practical, because we don't know the burst times of each process, could only use the past to predict future executions, and may starve long jobs(they may never execute)
-
Shortest Remaining Time First -- with preemption, assume min execution is one unit, it optimizes the avg waiting time similar to SJF
-
Round Robin -- handles fairness
- OS divides execution into time slices(or quanta)
- an individual time slice is called a quantum
- preempt if a process is still running at end of quantum and re-add to queue
- what are practical considerations for determining quantum length?
- if the time slice is gigantic, then it would become FCFS
- if it's too small, then processes get preempted all the time, it would waste time doing all the context switching thing
- does not reduce avg waiting time
Process Arrival time Burst time P1 0 7 P2 2 4 P3 4 1 P4 5 4 Scheduling Avg Waiting Time Avg Response Time Context Switch Times FCFS 5 - - SJF 4 - - SRTF 3 1 5 RR 7 2.75 7 -
-
For FCFS:
1 1 1 1 1 1 1 2 2 2 2 3 4 4 4 4 -
For SJF:
1 1 1 1 1 1 1 3 2 2 2 2 4 4 4 4 -
For SRTF:
1 1 2 2 3 2 2 4 4 4 4 1 1 1 1 1 -
For RR, suppose time slice is 3:
1 1 1 2 2 2 1 1 1 3 4 4 4 2 1 4 -
RR performance depends on Quantum Length and Job Length
- low response (low avg waiting time) if job lengths vary
- good interactivity (fair allocation of CPU)
- it has poor avg waiting time when jobs have similar lengths
-

Advanced Scheduling
-
Add priorities
- run higher priority processes first
- round-robin processes of equal priority
- can be preemptive or non-preemptive
-
priorities can be assigned as an integer
- In Linux,
-20is the highest priority while19is the lowest - we may lead processes to
starvationif there are a lot of higher priority processes - one solution to the starvation is to have OS dynamically change the priority, older processes that have not been executed in a long time increase priority
- In Linux,
-
Priority Inversion
- accidentally change the priority of a low priority process to a high one
- caused by dependecies, eg. a high priority depends on a low priority
- one solution is priority inheritance
-
foreground process and background process
- foreground ones are interactable and need good response time
- background ones may not need good response time, just throughput
-
scheduling strategies -- no "right answers", only trade-offs (haven't talked about multiprocessor scheduling yet in the course)
-
symmetric multiprocessing https://en.wikipedia.org/wiki/Symmetric_multiprocessing, we assume it here:
- all CPUs are connected to the same physical memory
- CPUs have their own private cache(at least the lowest levels)
-
use different queues for foreground processes and background processes
-
between queues, we need scheduling -- eg. RR between the queues and use a priority for each queue
-
scheduling strategies:
- use the same scheduling for all CPUs
- pros: good cpu utilization and fair to all processes
- cons: not scalable and poor cache locality
- used in Linux 2.4
- use per-cpu schedulers
- pros: easy to implement, scalable and good cache locality
- cons: load imbalance
- compromise between global and per-cpu strategies
- keep a global scheduler to re-balance per-cpu queues
- use processor affinity
- a simplified version of O(1) scheduler is used in Linux 2.6
- "Gang" scheduling -- coscheduling
- allows you to run a set of processes simultaneously (acting as a unit)
- requires a global context-switch across all CPUs
- use the same scheduling for all CPUs
-
real-time scheduling -- there are time constraints, either for a deadline or rate eg. audio, copilot
- a hard real-time system
- a soft real-time system, eg. Linux
-
Linux also implements FCFS and RR scheduling
SCHED_FIFO-- FCFS
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sched.h>
int main() {
struct sched_param param;
int priority = 30; // Priority for SCHED_FIFO must be > 0 and <= 99
// Set scheduling priority
param.sched_priority = priority;
// Attempt to set process scheduling policy to SCHED_FIFO
if (sched_setscheduler(0, SCHED_FIFO, ¶m) == -1) {
perror("sched_setscheduler failed");
exit(EXIT_FAILURE);
}
// If successful, the process now runs under SCHED_FIFO policy with the specified priority
printf("Successfully set process to SCHED_FIFO with priority %d\n", priority);
// Your real-time task logic here
while (1) {
// Simulate real-time task workload
printf("Running real-time task...\n");
sleep(1); // Just as an example, in real-time scenarios you'd avoid sleep
}
return 0;
}SCHED_FIFO, or First In, First Out, is one of the scheduling policies provided by the Linux kernel. This policy is used to schedule real-time tasks in a simple but effective way. UnderSCHED_FIFO, once a task starts running, it continues to run until it either voluntarily yields the processor, blocks on I/O, or is preempted by a higher priority task. Here's a brief overview of its characteristics:- Real-Time Scheduling Policy: It is part of the real-time scheduling policies that Linux supports, which also include
SCHED_RR(Round Robin) andSCHED_DEADLINE. - Priority-Based: Tasks are assigned priorities, with a higher priority task preempting lower priority tasks. The priorities range typically from 1 to 99, with 99 being the highest priority.
- Non-Preemptive: Within the same priority level,
SCHED_FIFOoperates non-preemptively. This means that a task will continue to run until it either voluntarily yields, blocks, or is preempted by a higher priority task. There is no time slicing involved for tasks of the same priority, unlikeSCHED_RRwhich uses time slices (quantum) to ensure that tasks of the same priority are run in a round-robin fashion. - Use Cases: It's suited for time-critical tasks where you need deterministic behavior. For instance, tasks that must respond to events in a fixed amount of time or that have strict timing requirements.
- Setting Policy and Priority: The scheduling policy and priority of a process can be set using the
sched_setschedulersystem call. Thesched_priorityfield of thesched_paramstructure is used to specify the priority of the task.
It's important to use
SCHED_FIFOcarefully, as it can lead to system unresponsiveness if a high-priority task does not yield the CPU, either by blocking on I/O or by explicitly callingsched_yield(). This policy is mostly used in systems where real-time processing is crucial and where tasks have well-defined execution times and resource requirements.SCHED_RR-- RR
SCHED_RR, or Round-Robin Scheduling, is another real-time scheduling policy provided by the Linux kernel, designed for time-sharing systems. LikeSCHED_FIFO,SCHED_RRis intended for tasks with real-time requirements, but it adds a time-slicing feature to ensure that all tasks of the same priority get a fair amount of CPU time. Here's an overview:
- Real-Time Scheduling: Part of Linux's real-time scheduling policies, alongside
SCHED_FIFOandSCHED_DEADLINE. - Priority-Based with Time Slicing: Tasks are still managed based on priorities (typically ranging from 1 to 99, with 99 being the highest priority). However, within the same priority level,
SCHED_RRcycles through tasks in a round-robin fashion, allocating a fixed time slice to each task before moving on to the next. - Preemptive: A running task will be preempted once its time slice expires, allowing the next task in the round-robin queue (of the same priority level) to run.
- Use Cases: Suitable for real-time tasks that require equal CPU time, ensuring that no task starves for processor time. It's often used in scenarios where multiple tasks need to respond promptly but can tolerate minor delays due to time-sharing.
- Setting Policy and Priority: Like with
SCHED_FIFO, you can set a process's scheduling policy and priority using thesched_setschedulersystem call.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sched.h>
int main() {
struct sched_param param;
int priority = 20; // Priority for SCHED_RR can be set within 1 to 99
// Set scheduling priority
param.sched_priority = priority;
// Attempt to set process scheduling policy to SCHED_RR
if (sched_setscheduler(0, SCHED_RR, ¶m) == -1) {
perror("sched_setscheduler failed");
exit(EXIT_FAILURE);
}
printf("Successfully set process to SCHED_RR with priority %d\n", priority);
// Your real-time task logic here
while (1) {
// Simulate real-time task workload
printf("Running under SCHED_RR...\n");
sleep(1); // Sleep is used here for demonstration; real-time tasks would likely avoid it
}
return 0;
}
-
Time Slice: The length of the time slice given to each task can vary depending on the system and kernel version. It's usually a few milliseconds.
-
Real-Time Performance: While
SCHED_RRensures fair CPU time for tasks of the same priority, the actual responsiveness and performance depend on the number of competing tasks and system load. -
Permissions: As with
SCHED_FIFO, setting theSCHED_RRpolicy typically requires elevated privileges.This scheduling policy is particularly useful for real-time applications that need fairness among tasks with the same priority, rather than allowing one task to monopolize the CPU until it yields or blocks.
-
soft real-time processes: always schedule the highest priority processes first
-
normal processes: adjust the priority based on aging
-
-
real-time processes are always prioritized
-
either be
SCHED_FIFOorSCHED_RR(0-99 static priority levels) -
SCHED_NORMALnormal scheduling apply to other processes(default is 0, ranges from [-20, 19]) -
processes can change their own priorities with system calls --
niceandsched_setschedulerBoth
nicevalues and thesched_setschedulerfunction in Linux are related to process scheduling, but they serve different purposes and operate under different scheduling policies. Here's an overview of how they differ and how they are used:-
niceValues- User-Space Control: The
nicevalue of a process is a user-space concept that influences the scheduling priority of processes within the standard Linux time-sharing scheduling policy (SCHED_OTHER). - Priority Adjustment: A process's
nicevalue can range from -20 (highest priority) to 19 (lowest priority). The defaultnicevalue for a process is 0. Adjusting thenicevalue affects the process's static priority, which the scheduler uses to determine how much CPU time the process will get relative to other processes. - Use Case: Primarily used for fine-tuning process priority under normal (non-real-time) conditions, allowing some processes to have higher or lower chances of getting CPU time. This is particularly useful in a multi-user environment or when running background tasks that shouldn't interfere with more critical foreground applications.
- Modification: The
nicevalue can be adjusted using theniceandrenicecommands in the shell, or through thesetprioritysystem call in code.
- User-Space Control: The
-
sched_setscheduler- Kernel-Level Control: This function allows changing the scheduling policy and priority of a process at the kernel level. It offers more granular control over how a process is scheduled compared to
nicevalues. - Supports Real-Time Policies: Unlike
nice, which only affects processes under theSCHED_OTHERpolicy,sched_setschedulercan be used to set real-time policies likeSCHED_FIFO,SCHED_RR, and alsoSCHED_OTHER,SCHED_BATCH, andSCHED_IDLE. - Priority Specification: For real-time policies (
SCHED_FIFOandSCHED_RR), it allows setting an exact priority within the real-time priority range (usually 1 to 99). This is crucial for real-time applications where precise control over execution order and timing is necessary. - Use Case: Essential for real-time and high-priority tasks where deterministic behavior, response time, or execution order is critical. It's also used to adjust the scheduling policy and priority of threads within a process.
- Modification: Requires root privileges or appropriate capabilities for setting real-time policies due to the potential impact on system behavior and performance.
- Kernel-Level Control: This function allows changing the scheduling policy and priority of a process at the kernel level. It offers more granular control over how a process is scheduled compared to
-
Comparison and Use in Code
nicefor Background or Less Critical Tasks: Adjusting thenicevalue is straightforward for tasks that do not require real-time execution but may need to be de-prioritized or given more CPU time in a shared environment.sched_setschedulerfor Real-Time and Critical Tasks: When deterministic behavior or specific scheduling characteristics are required,sched_setscheduleris the preferred choice. It's more complex to use correctly but provides the necessary control for real-time applications.
-
Example
Adjusting
nicevalue (shell command):renice 10 -p 12345 # Set the nice value of process with PID 12345 to 10Setting scheduling policy to
SCHED_FIFOwithsched_setscheduler(C code):#include <sched.h>
struct sched_param param;
param.sched_priority = 30; // Priority level for real-time tasks
if (sched_setscheduler(0, SCHED_FIFO, ¶m) == -1) {
perror("sched_setscheduler failed");
exit(EXIT_FAILURE);
}In summary,
nicevalues are suitable for general priority adjustments within conventional time-sharing scheduling, whilesched_setschedulerprovides comprehensive control for setting precise scheduling policies and priorities, including for real-time tasks.
-
-
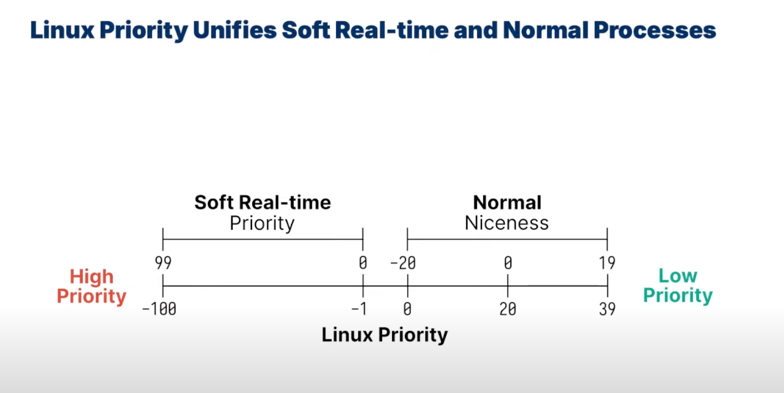
-
check processes'
PRIanNIusinghtop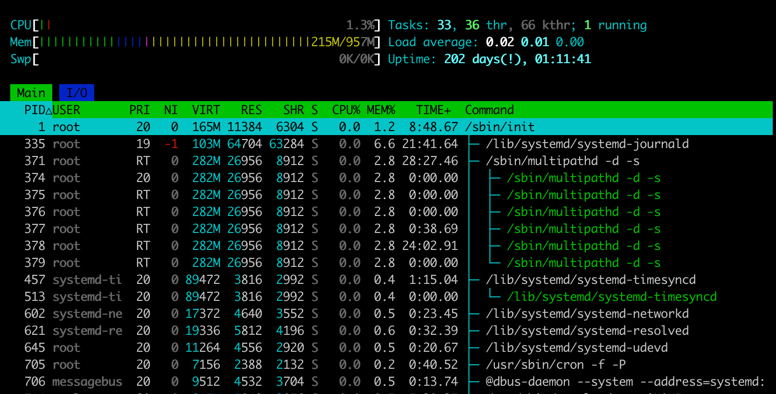
PRI>= 0, normal processesPRI< 0, soft real-time processes, niceness does not matter, always zero- if
PRIisRT, then the priority is -100
-

-
Ideal Fair Scheduling vs Complete Fair Scheduler
-
IFS -- fairest but impractical, as it causes too many context switches
-
CFS is the default process scheduler in Linux, introduced in version 2.6.23 (2007), designed to manage CPU resource allocation for executing processes in a way that maximizes overall CPU utilization and throughput. It replaced the previous
O(1)scheduler, bringing a more sophisticated approach to handling process priorities and ensuring fair CPU time distribution among processes.

-
Key Features of CFS:
-
Fairness: The primary goal of CFS is to provide a fair amount of CPU time to each runnable task, based on their priority and scheduling needs. The idea of fairness is implemented by modeling scheduling as if the system had an ideal, perfectly multitasking processor, where each task would receive an equal share of CPU time.
-
Virtual Runtime (vruntime): CFS uses a concept called "virtual runtime" to track how much CPU time each task has received. The scheduler attempts to minimize the difference in
vruntimeamong all tasks, ensuring that tasks get scheduled in a fair manner. The task with the smallestvruntimegets to run next. -
Red-Black Tree: The scheduler maintains a red-black tree (a type of self-balancing binary search tree) for all runnable tasks, indexed by their
vruntime. This structure allows the scheduler to quickly select the next task to run with the leastvruntime, ensuring efficient scheduling decisions. O(lgN) insert, delete, update, find minimum -
Group Scheduling: CFS supports group scheduling, allowing tasks to be grouped and each group to be allocated a fair share of the CPU. This is particularly useful in multi-user environments or in systems where tasks can be logically grouped to reflect their real-world interactions or dependencies.
-
Dynamic Priorities: While CFS aims to distribute CPU time equally, it still respects task priorities. Nice values (
nicecommand in Linux) influence a task's weight, affecting itsvruntimecalculation and thus its scheduling. Lower nice values (higher priority) lead to more CPU time.
-
-
Comparison with Other Schedulers
-
Real-Time Schedulers (
SCHED_FIFO,SCHED_RR): Unlike CFS, real-time schedulers are designed to meet the timing requirements of real-time applications, offering deterministic scheduling behavior. CFS is more about fair time-sharing and is not suitable for tasks with hard real-time constraints. -
Batch and Idle Schedulers (
SCHED_BATCH,SCHED_IDLE): These are specialized policies for batch processing and very low priority tasks, respectively. They use the CFS framework but adjust the scheduling behavior to optimize for throughput (batch) or to run tasks only when the system is idle.
-
CFS has significantly improved the way Linux handles multitasking, especially in systems with multiple processors, by ensuring that all processes get a fair share of the CPU, improving responsiveness and system utilization. It's a testament to the ongoing evolution of the Linux kernel to meet the needs of modern computing environments.
-
-
-

Virtual Memory
-
virtual mapping
-
virtual memory checklist
- Multiple processes must be able to co-exist
- Processes are not aware they are sharing physical memory
- Processes cannot access each others data (unless allowed explicitly)
- Performance close to using physical memory
- Limit the amount of fragmentation (wasted memory)
-
The smallest unit you can use to address memory is one byte (byte addressable)
-
Memory Management Unit (MMU)
- Maps virtual address to physical address, also checks permissions
- A page in virtual memory is called a page
- A page in physical memory is called a frame
-
-
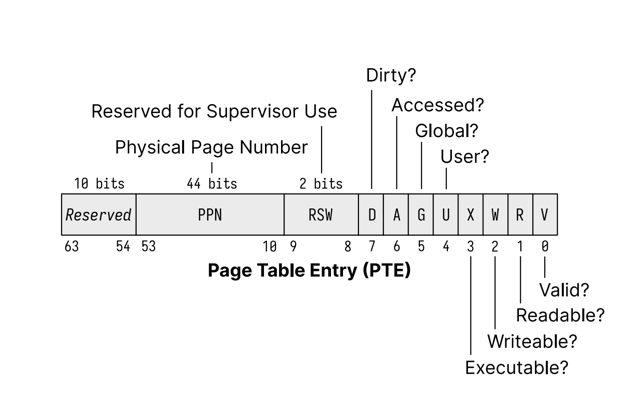
-
Each Process Gets Its Own Page Table
- When you fork a process, it will copy the page table from the parent
- Turn off the write permission so the kernel can implement copy-on-write
- There are 227 entries in the page table, each one is 8 bytes. This means the page table would be 1 GiB
- Note that RISC-V translates a 39-bit virtual to a 56-bit physical address, it has 10 bits to spare in the PTE and could expand
- So page size is 4096 bytes (size of offset field)
-
vfork-
vforkshares all memory with the parent -
It’s undefined behavior to modify anything
-
Only used in very performance sensitive programs
The
vforksystem call is used in Unix-like operating systems to create a new process without copying the page table of the parent process. It's similar tofork, but it's designed to be more efficient when the purpose is to immediately exec a new process. However, becausevforksuspends the parent process until the child process either callsexecorexit, and because it shares the memory space with the parent, it can lead to undefined behavior if not used carefully. It's generally recommended to useforkor, better yet,posix_spawnfor creating new processes due to these potential issues.#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void) {
pid_t child_pid;
int status;
child_pid = vfork();
if (child_pid == -1) {
// vfork failed
perror("vfork");
exit(EXIT_FAILURE);
} else if (child_pid == 0) {
// Child process
printf("This is the child process. PID: %d\n", getpid());
execl("/bin/ls", "ls", "-l", NULL); // Replace the child process with "ls -l"
// If execl fails:
perror("execl");
_exit(EXIT_FAILURE); // Use _exit instead of exit to avoid flushing stdio buffers of the parent
} else {
// Parent process
printf("This is the parent process. PID: %d\n", getpid());
waitpid(child_pid, &status, 0); // Wait for the child to finish
if (WIFEXITED(status)) {
printf("Child exited with status %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Child terminated by signal %d\n", WTERMSIG(status));
}
}
return EXIT_SUCCESS;
}This code snippet demonstrates a basic use of
vforkfor creating a child process that immediately executes thels -lcommand usingexecl. The parent process waits for the child process to finish before continuing. Note the use of_exitin the child process instead ofexit. This is crucial becauseexitperforms cleanup tasks that may interfere with the parent process due to the shared memory space when usingvfork.
-
-
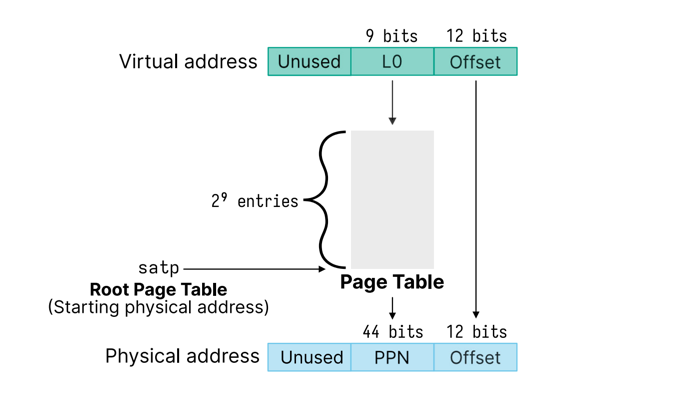
-
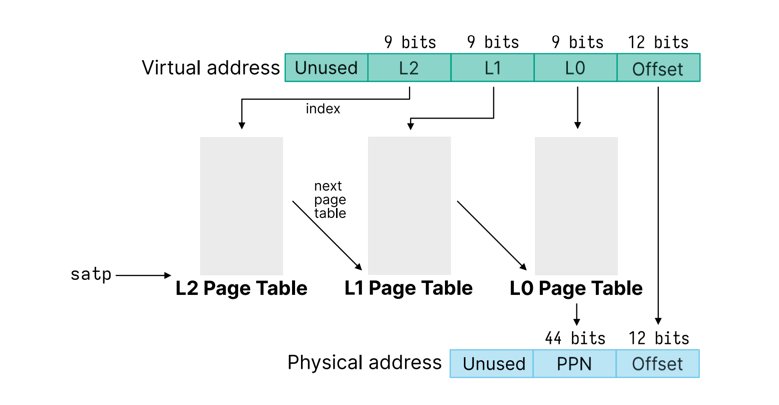
-
Page allocation uses a free list(linked list)
-
30 bit virtual address (sv 30)
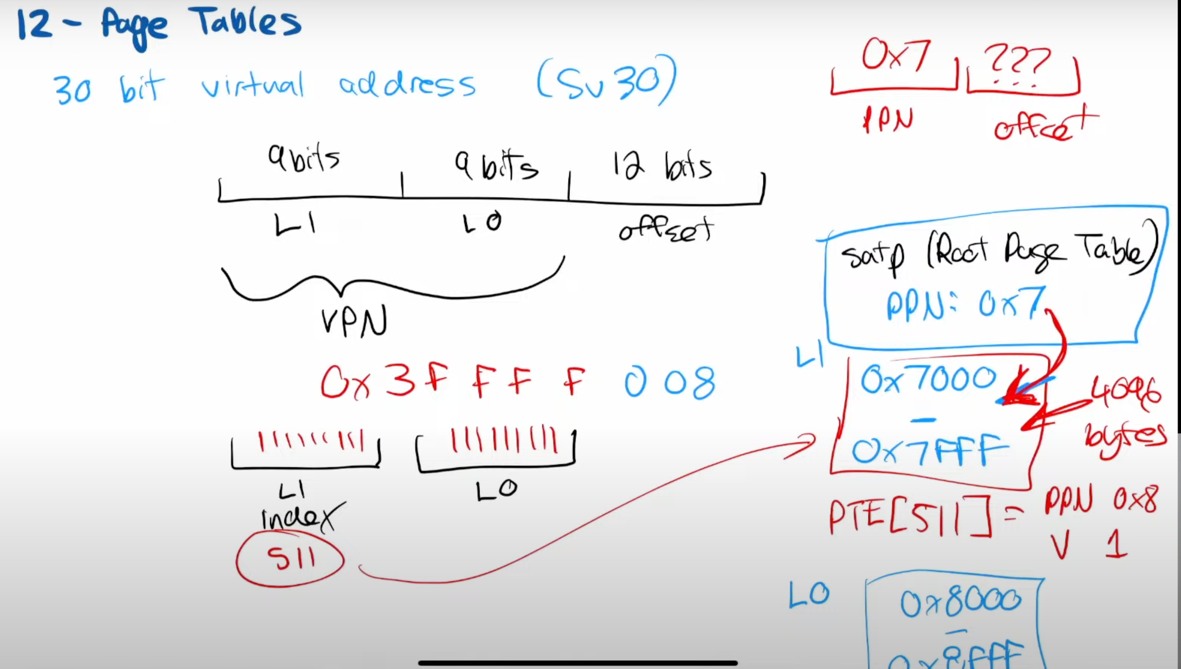
-
A Translation Look-Aside Buffer (TLB) Caches PTEs
- Effective Access Time (EAT)
- Context Switches Require Handling the TLB, You can either flush the cache, or attach a process ID to the TLB
- Most implementation just flush the TLB
- RISC-V uses a sfence.vma instruction to flush the TLB
- On x86 loading the base page table will also flush the TLB
-
The Kernel Can Provide Fixed Virtual Addresses
- It allows the process to access kernel data without using a system call
- For instance
clock_gettimedoes not do a system call. It just reads from a virtual address mapped by the kernel
-
Page Faults
- a type of exception for virtual memory access
- Generated if it cannot find a translation, or permission check fails
- This allows the operating system to handle it, we could lazily allocate pages, implement copy-on-write, or swap to disk
-
MMU -- the hardware that uses page tables
- Be a single large table (wasteful, even for 32-bit machines)
- Use the kernel allocated pages from a free list
- Be a multi-level to save space for sparse allocations
- Use a TLB to speed up memory accesses
-
write a MMU-SIM
-
memory alignment
- is address 0xEC 8 bytes aligned? -- no, 0xEC is 236 in decimal, which is not an 8 or a multiple of 8
-
How many page tables do we need?
-
assume the program uses 512 pages
-
minimum number of page tables: 1 + 1 + 512 = 514
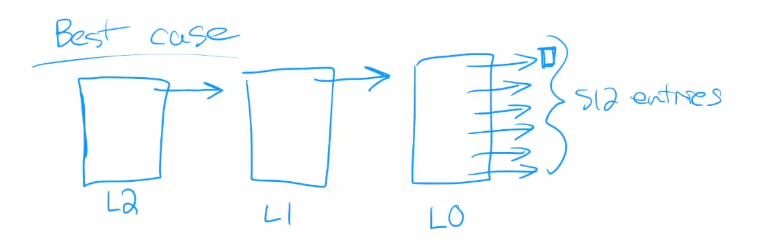
- maximum number of page tables: 1 + 512 + 512 = 1025
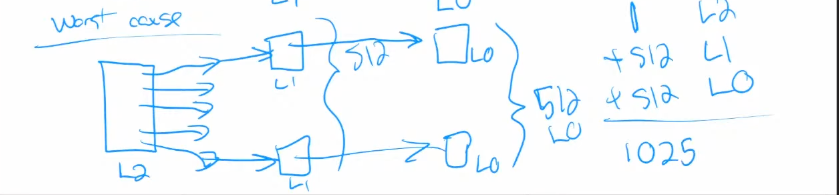
-
-
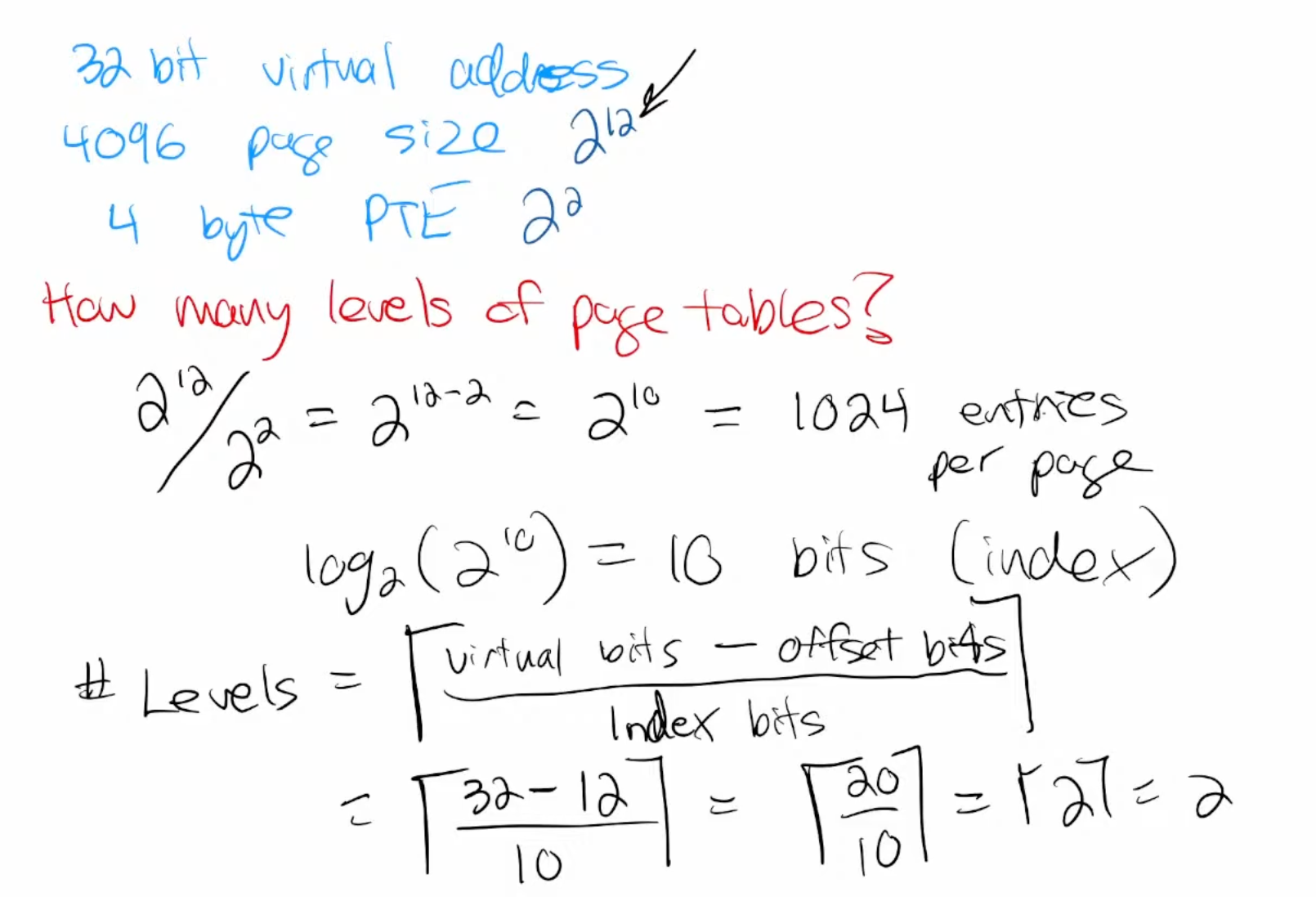
-
processes use a register like
satpto set the root page table -
the more levels, the slower performance
-
a 32-bit machine can address up to 4GB of memory at most is generally accurate but comes with nuances worth discussing:
-
A 32-bit system uses 32 bits to address memory. Since each bit can have 2 states (0 or 1), a 32-bit address can represent (2^32) different values. Calculating this gives us:
2^32 = 4,294,967,296
This number represents the total count of unique addresses that can be represented, and since each address points to a byte in memory, it equals 4GB (gigabytes) of memory. Therefore, in theory, a 32-bit system is limited to directly addressing a maximum of 4GB of memory.
-
Nuances and Exceptions
-
Physical Address Extension (PAE): To overcome this limitation, some 32-bit processors support PAE, which extends the physical memory addressability capabilities beyond 4GB. PAE allows for up to 36 bits of physical addressing, which supports up to 64GB of physical memory. However, even with PAE, individual processes on a 32-bit operating system typically remain limited to a 2GB or 3GB user address space, depending on the system configuration.
-
Operating System and Application Limitations: The way an operating system and applications utilize memory can also affect how much memory is actually usable. For instance, some 32-bit operating systems might reserve a portion of the addressable space for system use, limiting applications to less than 4GB even if the hardware could theoretically address more with PAE.
-
Memory Mapping and Devices: In some configurations, parts of the address space are reserved for memory-mapped IO devices. This means that not all of the 4GB address space is available for RAM, as some addresses are used to communicate with other hardware devices.
-
-
Practical Implications
For most users, the 4GB limit means that upgrading a 32-bit system with more than 4GB of RAM will not result in any performance benefit for memory usage, unless the system and OS support and are configured to use PAE or similar technologies. However, transitioning to a 64-bit architecture, where the addressable memory space is vastly larger, is often a more practical solution for overcoming the memory limitations associated with 32-bit systems.
-
-
caching is the solution to the low performance of using page tables for memory access
- TLB(Translation Look-Aside Buffer) caches PTE
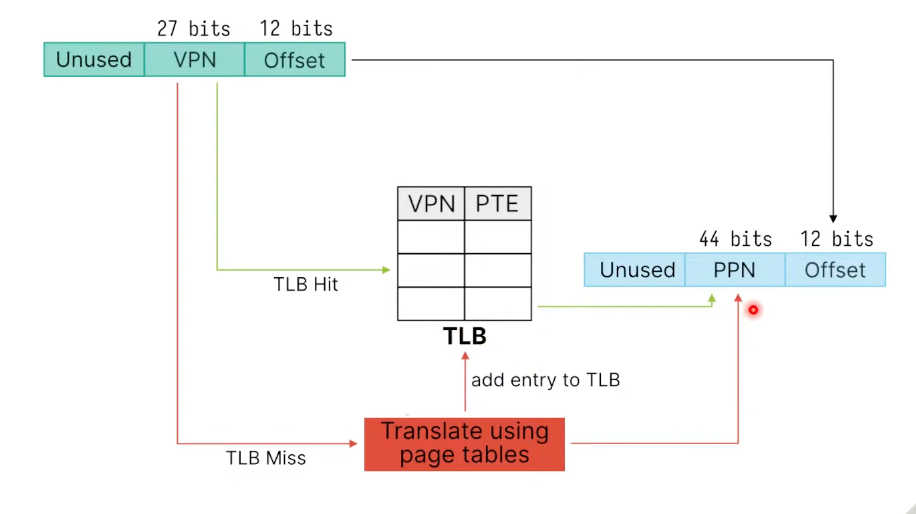
- Effective Access Time (EAT)

-
The
sbrkfunction is a system call used in Unix-like operating systems to manage the program's heap memory. It stands for "set break" and adjusts the end of the data segment of the calling process, effectively allocating or deallocating memory. The "break" is the end of the heap area in a process's memory space.-
Allocation: When sbrk is called with a positive integer, it increases the program's data segment by that many bytes. If the space is available, sbrk allocates the additional heap memory and returns a pointer to the start of the newly allocated space.
-
Deallocation: When called with a negative integer, sbrk decreases the program's data segment, effectively deallocating memory that was previously allocated with sbrk.
-
Current Break: Calling sbrk with an argument of 0 returns the current location of the break, allowing programs to query the size of the heap.
#include <unistd.h>
#include <stdio.h>
int main() {
// Allocate space for 10 integers on the heap
int* heap_array = sbrk(10 * sizeof(int));
if (heap_array == (void*)-1) {
// Allocation failed
perror("sbrk failed");
return 1;
}
// Use the allocated memory
for (int i = 0; i < 10; i++) {
heap_array[i] = i * i;
}
// Print the allocated memory
for (int i = 0; i < 10; i++) {
printf("%d ", heap_array[i]);
}
printf("\n");
// Deallocate the memory: Note that deallocating with sbrk is tricky and not generally recommended.
// This example does not deallocate memory because doing it correctly requires tracking the allocated size
// and ensuring no other allocations have occurred in the meantime. In real applications, use `free` instead.
return 0;
} -
-
process's address space
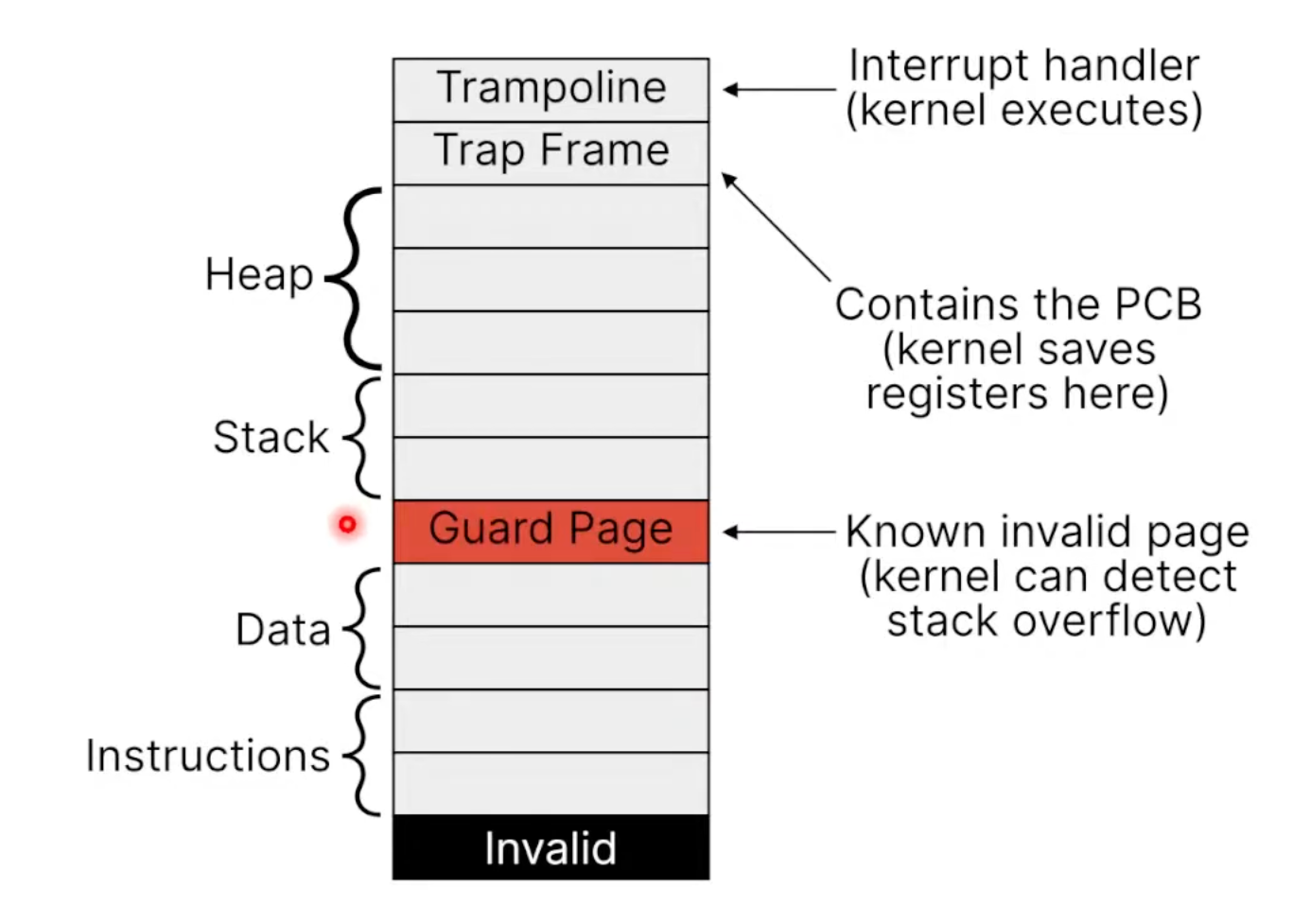
Priority Scheduling and Memory Mapping
-
Dynamic Priority Scheduling
- also called feedback scheduling
- set time slices and measure CPU usage
- increase the priority of processes that do not use their time slice
- decrease the priority of processes that use their full time slice
- timer interrupts frequency, time slice, priority interval
-
mmap-
it takes six arguments:
void *addr: suggested starting address (NULL means you don’t care)size_t length: number of bytes to mapint prot: protection flags (read/write/execute)int flags: mapping flags (shared/private/anonymous), anonymous means the mapping isn’t backed by a fileint fd: file descriptor to map (ignored for anonymous)off_t offset: offset to start the mapping (must be a multiple of page size)
-
mmapis lazy- It just sets up the page tables, it doesn’t actually read from the file
- It would create an invalid PTE during the mmap call
- The kernel uses the remaining bits of the PTE for bookkeeping where on the disk is this entry
- The first access to the page would generate a page fault, the kernel would then read from disk into memory. This ensures only the used parts of the file get read
int main(void){
int fd = open("mmap.c", O_RDONLY);
assert(fd==3);
struct stat stat;
assert(fstat(fd, &stat)==0);
char* data = mmap(NULL, stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
assert(data != MAP_FAILED);
assert(close(fd)==0);
for (int i=0; i < stat.st_size; ++i) {
printf("%c", data[i]);
}
assert(munmap(data, stat.st_size) == 0);
return 0;
} -
-
Q: https://github.com/ggerganov/llama.cpp/discussions/638 How does an approximately 20 GB file only use 5.8 GB of real memory?
A:

Threads
-
concurrency vs parallelism
Definition Goal Concurrency Switching between two or more things (can you get interrupted -- Y) Make progress on multiple things Parallelism Running two or more things at the same time (are they independent -- Y) Run as fast as possible -
threads vs processes
Process Thread Independent code / data / heap Shared code / data / heap Independent execution Must live within an executing process Has its own stack and registers Has its own stack and registers Expensive creation and context switching Cheap creation and context switching Completely removed from OS on exit Stack removed from process on exit -
#include <pthread.h>compile and link the pthread library, all the pthread functions have docs in themanpages -
create threads using
pthread_create
-
int pthread_join(pthread_t thread, void** retval)thewaitequivalent for threads -
exitfor threadsvoid pthread_exit(void *retval); -
detached threads
int pthread_detach(pthread_t thread); -
Joinable threads (the default) wait for someone to call
pthread_jointhen they release their resources Detached threads release their resources when they terminate -
#include <pthread.h>
#include <stdio.h>
void* run(void*) {
printf("In run\n");
return NULL;
}
int main() {
pthread_t thread;
pthread_create(&thread, NULL, &run, NULL);
printf("In main\n");
pthread_join(thread, NULL);
} -
#include <pthread.h>
#include <stdio.h>
void* run(void*) {
printf("In run\n");
return NULL;
}
int main() {
pthread_t thread;
pthread_create(&thread, NULL, &run, NULL);
pthread_detach(thread);
printf("In main\n");
pthread_exit(NULL);
} -
running code below shows a stack size of 8MiB(on most Linux systems)
size_t stacksize;
pthread_attr_t attributes;
pthread_attr_init(&attributes);
pthread_attr_getstacksize(&attributes, &stacksize);
printf("Stack size = %i\n", stacksize);
pthread_attr_destroy(&attributes); -
set a thread state to joinable --
pthread_attr_setdetachstate(&attributes, PTHREAD_CREATE_JOINABLE); -
multithreding models
-
user threads
-
kernel threads
-
For pure user-level threads (again, no kernel support):
• Very fast to create and destroy, no system call, no context switches
• One thread blocks, it blocks the entire process (kernel can’t distinguish)
-
For kernel-level threads:
• Slower, creation involves system calls
• If one thread blocks, the kernel can schedule another one
-
all threading libraries we use run in user mode, the thread library maps user threads to kernel threads
-
the thread library maps user threads to kernel threads
- many-to-one: threads completely implemented in user-space, the kernel only sees one process, it is pure user-space implementation
- one-to-one: one user thread maps directly to one kernel thread, the kernel handles everything, it is just a thin wrapper around the system calls(most used)
- many-to-many: many user-level threads map to many kernel level threads, it is a hybrid approach, # of user-level threads > # of kernel-level threads
-
-
when calling
fork, Linux only copies the thread that called it into a new process (ignoring other threads that are in the same process),pthread_atforkcontrols it -
signals are sent to a process, Linux will just pick one random thread to handle the signal
-
instead of
many-to-many, we could use a thread pool:- The goal of many-to-many thread mapping is to avoid creation costs
- A thread pool creates a certain number of threads and a queue of tasks (maybe as many threads as CPUs in the system)
- As requests come in, wake them up and give them work to do
- Reuse them, when there’s no work, put them to sleep
Sockets
-
Servers:
- create the socket
- bind: attach the socket to some location(a file, IP:port, etc)
- listen: accept connections and set the queue limit
- accept: return the next incoming connection for you to handle
-
Clients:
- create the socket
- connect to some location, the socket can now send/receive data
-
The
socketsystem call sets the protocol and type of socketThe
socket(int domain, int type, int protocol)function is a fundamental system call used in network programming, available in various operating systems including Unix/Linux-based systems. It's used to create a socket, which is an endpoint for communication, allowing processes within the same or different computers to communicate with each other, typically over a network.Here's a breakdown of the parameters:
-
domain: This parameter specifies the communication domain or address family of the socket, dictating the protocol family to be used. Common values include:AF_INET: For IPv4 Internet protocols.AF_INET6: For IPv6 Internet protocols.AF_UNIXorAF_LOCAL: For local communication within the same machine using Unix domain sockets.
-
type: This parameter specifies the communication semantics, mainly how data is transmitted. Common values include:SOCK_STREAM: Provides sequenced, reliable, two-way, connection-based byte streams (e.g., TCP). Use this for a connection-oriented service.SOCK_DGRAM: Supports datagrams (connectionless, unreliable messages of a fixed maximum length, e.g., UDP).SOCK_RAW: Allows direct access to lower-level protocols, which can be used for more fine-grained control over your network communication.
-
protocol: This specifies a particular protocol to be used with the socket. Normally, only a single protocol exists to support a particular socket type within a given protocol family, in which case protocol can be specified as 0. However, if there are multiple protocols, you can use this parameter to choose one. For example, to specify the TCP protocol for anAF_INETsocket, you'd use theIPPROTO_TCPprotocol.
The function returns a socket descriptor, a small non-negative integer, which acts as a handle to the newly created socket. This descriptor can be used in subsequent operations on the socket, like connecting to a remote host, sending or receiving data, or closing the socket. If the function fails, it returns -1, and
errnois set to indicate the error.Here's a simple example in C:
#include <sys/types.h>
#include <sys/socket.h>
int main() {
int sockfd;
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
// Error handling
}
// Use the socket descriptor `sockfd`
return 0;
}In this example, a socket descriptor
sockfdis created for the IPv4 Internet protocol family (AF_INET) using the TCP protocol (SOCK_STREAM), with the system choosing the appropriate protocol (0). -
-
stream sockets use TCP, while datagram sockets use UDP
-
the
bindsystem call sets a socket to an address-
int bind(int socket, const struct sockaddr *address, socklen_t address_len); -
The
bindfunction is a key component in network programming, especially when working with sockets in the C programming language. It's used to associate a socket with a specific local IP address and port number. This step is essential for servers that need to listen for incoming connections on a specific port. Here's a breakdown of its parameters and its return value:-
int socket: This is the file descriptor that refers to the socket that was created with the
socketfunction. -
*const struct sockaddr address: This parameter points to a
sockaddrstructure that contains the local IP address and port number to bind to the socket. The actual structure you use (such assockaddr_infor IPv4 orsockaddr_in6for IPv6) will depend on the address family of the socket. You'll typically cast a pointer to your specific address structure to a pointer tosockaddrwhen callingbind. -
socklen_t address_len: This specifies the size, in bytes, of the address structure pointed to by the
addressparameter. This ensures that the correct amount of address data is used by the function.
Return Value: On success,
bindreturns 0. On error, it returns -1, anderrnois set to indicate the error. Some common error codes includeEACCES(permission denied),EADDRINUSE(the address is already in use), andEBADF(the file descriptor is not a valid index in the descriptor table).Here's a simplified example of using
bindin a server application: -
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0); // Create a socket
if (sockfd < 0) {
// Handle error
}
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = INADDR_ANY; // Bind to any local address
addr.sin_port = htons(12345); // Specify port to listen on
if (bind(sockfd, (struct sockaddr *)&addr, sizeof(addr)) < 0) {
// Handle error
}
// Proceed to listen on the socket and accept connections
}In this example, a TCP socket is created with
socket, andbindis used to associate it with all local IP addresses (INADDR_ANY) and a specific port number (12345). This setup allows the server to accept incoming connections on that port. -
-
the
listensystem call-
int listen(int socket, int backlog); -
The
listenfunction is a system call used in network programming, specifically within the context of socket programming in UNIX or Linux-based systems. This function is crucial for setting up a socket to accept incoming connections. Here's a brief overview of its parameters and usage:-
int socket: This is the file descriptor that refers to a socket. The socket must be of a type that supports connection-based communication, such asSOCK_STREAM(for TCP connections) orSOCK_SEQPACKET(for reliable, connection-based, ordered delivery of packets). Before callinglisten, the socket should be created with thesocketfunction and bound to a local address with thebindfunction. -
int backlog: This parameter specifies the maximum length of the queue of pending connections. In other words, it defines how many pending connections can be queued up at the socket at any one time before new connection attempts are rejected. The actual maximum length of the queue may be influenced by the underlying operating system and its configuration.
Here's a simplified usage pattern for setting up a server socket to listen for incoming connections:
- Create a socket using the
socketfunction. - Bind the socket to an address (usually a specific port on the host machine) using the
bindfunction. - Listen on the socket with the
listenfunction. - Accept connections using the
acceptfunction. This step is typically performed in a loop, allowing the server to handle multiple clients, either sequentially or concurrently, depending on the design.
The
listenfunction prepares the socket to accept incoming connections, transitioning it from a closed state to a listening state where it can accept connections. After callinglisten, the server typically callsacceptto actually accept an incoming connection and get a new socket that is used for communication with the connecting client.Here is a basic example in C:
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0); // Create a socket
struct sockaddr_in server_addr;
// Initialize server address structure
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(12345);
bind(sockfd, (struct sockaddr *) &server_addr, sizeof(server_addr)); // Bind the socket
listen(sockfd, 5); // Listen on the socket, with a maximum of 5 pending connections
// Server loop here: accept connections, handle them, etc.
return 0;
}In this example,
AF_INETspecifies the address family (IPv4 in this case),SOCK_STREAMspecifies the socket type (stream socket, typically used for TCP), and0specifies the default protocol (TCP for stream sockets). The server listens on port12345and allows up to 5 pending connections in the queue. -
-
the
acceptsystem callThe
acceptfunction is a key part of the BSD socket API, used in network programming to accept a new connection on a socket. Here's a breakdown of its signature:int accept(int socket, struct sockaddr *restrict address, socklen_t *restrict address_len);-
socket: This is the file descriptor that refers to a socket that has been put into a listening state with the
listen()call. This socket is set up to listen for incoming connections on a specific port. -
address: This parameter is a pointer to a
sockaddrstructure. This structure is filled with the address information of the connecting entity, for example, an IP address and port number for IPv4 connections. The exact structure used (e.g.,sockaddr_infor IPv4,sockaddr_in6for IPv6) depends on the address family of the socket. -
address_len: A pointer to a
socklen_tvariable. Initially, it should contain the size of theaddressstructure that is passed to the function. Upon return, it will contain the actual length (in bytes) of the address returned.
Return Value:
- On success,
acceptreturns a non-negative integer that is a descriptor for the accepted socket. This new socket descriptor can be used for subsequent read and write operations with the connecting client. - On error,
-1is returned, anderrnois set appropriately to indicate the error.
Error Codes (
errno):EAGAINorEWOULDBLOCK: The socket is marked non-blocking, and no connections are present to be accepted.EBADF: The descriptor is invalid.ECONNABORTED: A connection has been aborted.EINTR: The system call was interrupted by a signal before a valid connection arrived.EINVAL: The socket is not listening for connections, or theaddress_lenargument is invalid for the address family.EMFILE: The per-process limit on the number of open file descriptors has been reached.ENFILE: The system limit on the total number of open files has been reached.ENOBUFSorENOMEM: Insufficient memory is available.ENOTSOCK: The descriptor references a file, not a socket.EOPNOTSUPP: The referenced socket is not of typeSOCK_STREAMand thus does not accept connections.
The
acceptfunction is widely used in TCP server applications to accept incoming client connections. After accepting a connection, the server typically spawns a new thread or process to handle communication with the newly connected client, allowing the main server process to go back to accepting additional incoming connections. -
-
-
the
connectsystem callThe
connectfunction is used in network programming to establish a connection to a server from a client. It's a part of the BSD socket API, allowing a socket to connect to a specified address. Here's a closer look at its syntax:int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);-
sockfd: This is the file descriptor representing the socket that will be used to establish the connection. This socket should be created with the
socket()call before usingconnect. -
addr: A pointer to a
sockaddrstructure that contains the destination address to connect to. This structure holds the IP address and port number of the server. The actual structure used (such assockaddr_infor IPv4 addresses) depends on the address family of the socket. -
addrlen: Specifies the size, in bytes, of the address structure pointed to by
addr.
Return Value:
- On success,
connectreturns0. - On error, it returns
-1, anderrnois set to indicate the error.
Common Error Codes (
errno):EACCES: Permission to connect to the specified address is denied.ECONNREFUSED: No one is listening on the remote address.ETIMEDOUT: The attempt to connect timed out before a connection was made.EHOSTUNREACH: The host is unreachable.EINPROGRESS: The socket is non-blocking, and the connection cannot be completed immediately. It indicates that the connection is in progress.EALREADY: A non-blocking connection attempt is already in progress for the specified socket.EINVAL: Invalid argument passed.ENETUNREACH: The network is unreachable from this host.EISCONN: The socket is already connected.EADDRNOTAVAIL: The specified address is not available from the local machine.
The
connectfunction is primarily used by TCP client applications to establish a connection to a TCP server. In the context of a UDP protocol,connectmight be used to set a default address forsendandrecvcalls (since UDP is connectionless and does not actually establish a connection). -
Locks
-
Data Races Can Occur When Sharing Data
-
A data race is when two concurrent actions access the same variable and at least one of them is a write operation
-
Atomic operations are indivisible, which means they cannot be preempted, but between two atomic instructions, you may be preempted
-
-
Three-Address Code
- Intermediate Code Used by Compilers
- https://en.wikipedia.org/wiki/Three-address_code
- TAC is mostly used for analysis and optimization by compilers
-
GIMPLE is the TAC used by
gcc- To see the GIMPLE representation of your compilation use:
-fdump-tree-gimpleflag - To see all the three address code generated by the compiler (gcc) use:
-fdump-tree-allflag
- To see the GIMPLE representation of your compilation use:
-
A Critical Section Means Only One Thread Executes Instructions
-
Safety (aka mutual exclusion): There should only be a single thread in a critical section at once
-
Liveness (aka progress):
- If multiple threads reach a critical section, one must proceed
- The critical section can’t depend on outside threads
- You can mess up and deadlock (threads don’t make progress)
-
Bounded waiting (aka starvation-free): A waiting thread must eventually proceed
-
-
Critical Sections Should Also Have Minimal Overhead
- Efficient -- You don’t want to consume resources while waiting
- Fair -- You want each thread to wait approximately the same time
- Simple -- It should be easy to use, and hard to misuse
-
Layers of Synchronization
Semaphores
-
Locks Ensure Mutual Exclusion
- A lock is a binary semaphore
- It can be locked or unlocked
- If a thread tries to lock a locked lock, it blocks until the lock is unlocked
-
Semaphores are Used for Signaling
-
A semaphore is a generalization of a lock
-
It can be locked or unlocked
-
If a thread tries to lock a locked semaphore, it blocks until the semaphore is unlocked
-
A semaphore can be unlocked by a thread that doesn’t own it
-
Semaphores have a value that is shared between threads
-
It has two fundamental operations wait and post
waitdecrements the value atomicallypostincrements the value atomically
-
-
Semaphore API is smilar to locks
pthread-
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_wait(sem_t *sem);
int sem_post(sem_t *sem);
int sem_destroy(sem_t *sem);
-
-
Use a Semaphore as a Mutex
-
static sem_t sem; /* New */
static int counter = 0;
void* run(void* arg) {
for (int i = 0; i < 100; ++i) {
sem_wait(&sem); /* New */
++counter;
sem_post(&sem); /* New */
}
}
int main(int argc, char *argv[]) {
sem_init(&sem, 0, 1); /* New */
/* Initialize, create, and join multiple threads */
printf("counter = %i\n", counter);
}
-
-
Producer/Consumer Problem
- A producer thread produces data
- A consumer thread consumes data
- The producer and consumer share a buffer
- The producer can’t produce if the buffer is full
- The consumer can’t consume if the buffer is empty
- The producer and consumer can’t access the buffer at the same time
-
solve the problem by using semaphores
#include <semaphore.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define BUFFER_SIZE 10
#define PRODUCER_COUNT 10
#define CONSUMER_COUNT 10
int buffer[BUFFER_SIZE];
int in = 0;
int out = 0;
sem_t empty;
sem_t full;
sem_t mutex;
void* producer(void* arg) {
for (int i = 0; i < 100; ++i) {
sem_wait(&empty);
sem_wait(&mutex);
buffer[in] = i;
in = (in + 1) % BUFFER_SIZE;
sem_post(&mutex);
sem_post(&full);
}
return NULL;
}
void* consumer(void* arg) {
for (int i = 0; i < 100; ++i) {
sem_wait(&full);
sem_wait(&mutex);
int data = buffer[out];
out = (out + 1) % BUFFER_SIZE;
sem_post(&mutex);
sem_post(&empty);
printf("Consumer %i: %i\n", (int)arg, data);
}
return NULL;
}
int main() {
sem_init(&empty, 0, BUFFER_SIZE);
sem_init(&full, 0, 0);
sem_init(&mutex, 0, 1);
pthread_t producers[PRODUCER_COUNT];
pthread_t consumers[CONSUMER_COUNT];
for (int i = 0; i < PRODUCER_COUNT; ++i) {
pthread_create(&producers[i], NULL, &producer, (void*)i);
}
for (int i = 0; i < CONSUMER_COUNT; ++i) {
pthread_create(&consumers[i], NULL, &consumer, (void*)i);
}
for (int i = 0; i < PRODUCER_COUNT; ++i) {
pthread_join(producers[i], NULL);
}
for (int i = 0; i < CONSUMER_COUNT; ++i) {
pthread_join(consumers[i], NULL);
}
sem_destroy(&empty);
sem_destroy(&full);
sem_destroy(&mutex);
return 0;
} -
Semaphores can ensure mutex and proper order
- Semaphores contain an initial value you choose
- You can increment the value using post
- You can decrement the value using wait (it blocks if the current value is 0
- You still need to be prevent data races
Disks
-
SSD -- use NAND flash
-
pros
- No moving parts or physical limitations
- Higher throughput, and good random access
- More energy efficient
- Better space density
-
cons
- More expensive
- Lower endurance (number of writes)
- More complicated to write drivers for
-
-
NAND flash uses pages and blocks
- erasing is done per block
- writing is slow
-
OS can speed up SSDs
- OS can use TRIM to inform the SSD a block is unused
- SSD can erase the block without moving overhead
-
Single Large Expensive Disk (SLED) can lead to single point of failure
-
Redundant Array of Independent Disks (RAID)
- Data distributed on multiple disks
- Use redundancy to prevent data loss
- Use redundancy to increase throughput
-
RAID 0 -- a striped volume, for performance only
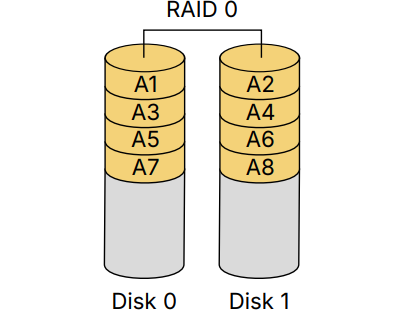
- faster parallel access but any disk failure results in a data loss
-
RAID 1 Mirrors all data across all disks -- simple but wasteful
-
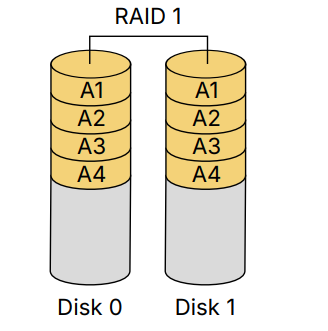
-
good reliability and read perform, but high cost for redundancy and write performance is the same as a single disk
-
RAID 4 Introduces Parity (by using
xor)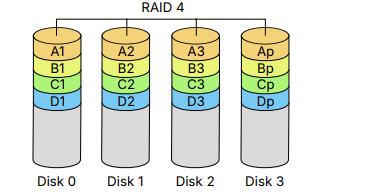
- requires at least 3 drives
- get N-1 times of performance but write perform can suffer (every write needs an extra write to parity disk)
-
-
RAID 5 Distributes Parity Across All Disks
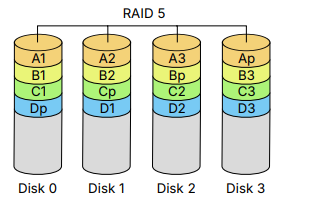
- an improved version of RAID 4 -- write performance is improved, no longer a bottlnect on a single parity drive
-
RAID 6 Adds Another Parity Block Per Stripe
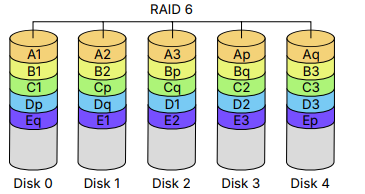
- can withstand two drives dying
- requires at least 4 drives
- write perform is slightly less than RAID 5, due to another parity calculation
-
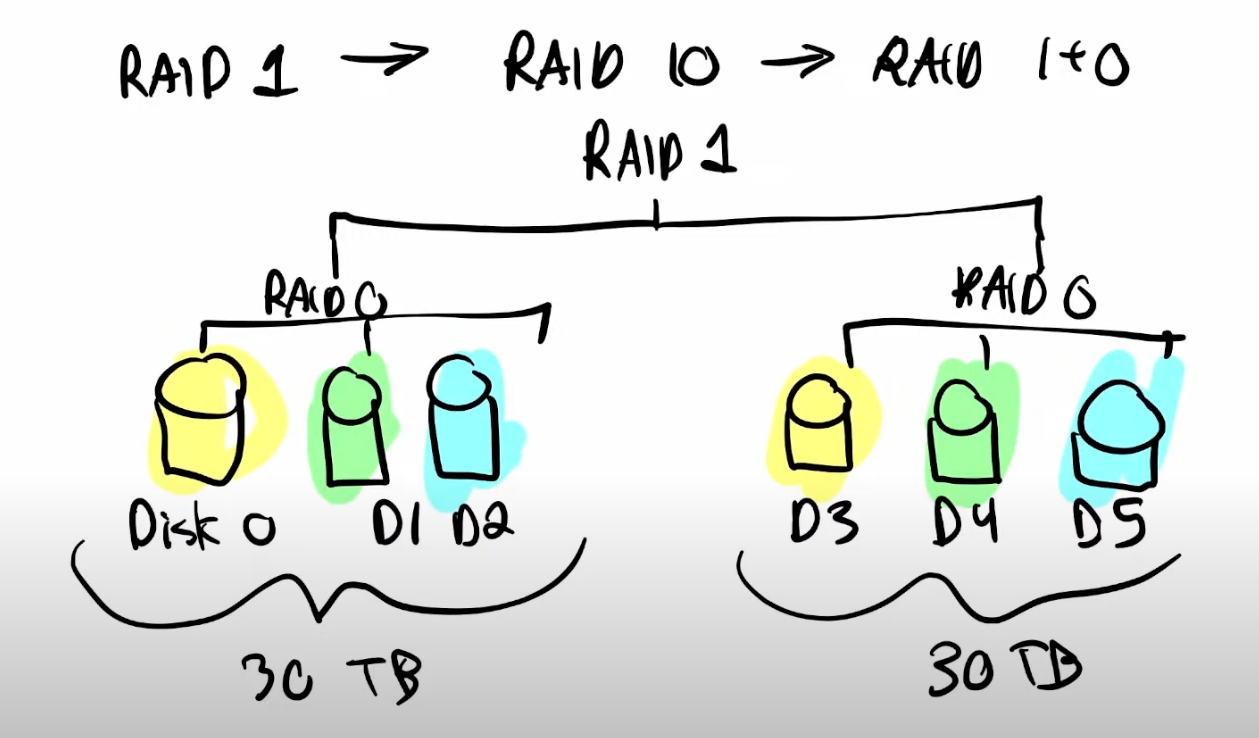 -- actually fast to repair
-- actually fast to repair
Filesystems
-
access files -- sequentially or randomly
- sequential access: each read advances the position inside the file, and writes are appended and the position set to the end afterwards
- random access: records can be read/written to the file in any order, a specific position is required for each operation
-
Disks enable persistence
- SSDs are more like RAM except accessed in pages and blocks
- SSDs also need to work with the OS for best performance (TRIM)
- Use RAID to tolerate failures and improve performance using multiple disks
int open(const char *pathname, int flags, mode_t mode);
// flags can specify which operations: O_RDWR,O_WRONLY, O_RDWR
// also: O_APPEND moves the position to the end of the file initially
off_t lseek(int fd, off_t offset, int whence);
// lseek changes the position to the offset
// whence can be one of: SEEK_SET, SEEK_CUR, SEEK_END
// set makes the offset absolute, cur and end are both relative -
the Directory API
DIR *opendir (char *path); // open directory
struct dirent *readdir(DIR *dir); // get next item
int closedir (DIR *dir); // close directory
void print_directory_contents (char *path) {
DIR *dir = opendir(path);
struct dirent *item;
while (item = readdir(dir)) {
printf("- %s\n", item->d_name);
}
closedir(path);
} -
file tables are stored in the PCB (system-wide global open file table)
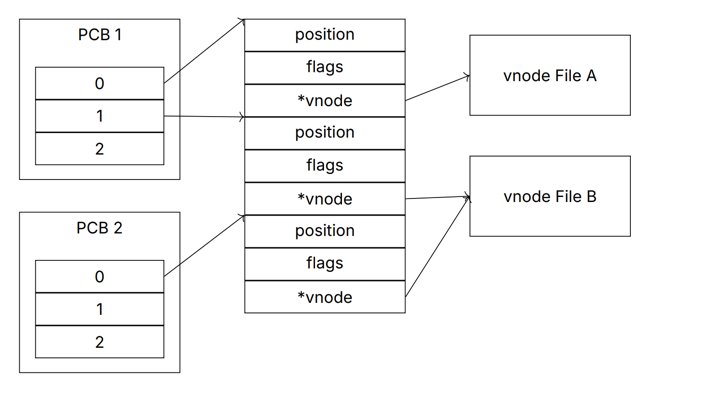
-
open("todo.txt", O_RDONLY);
fork();
open("b.txt", O_RDONLY);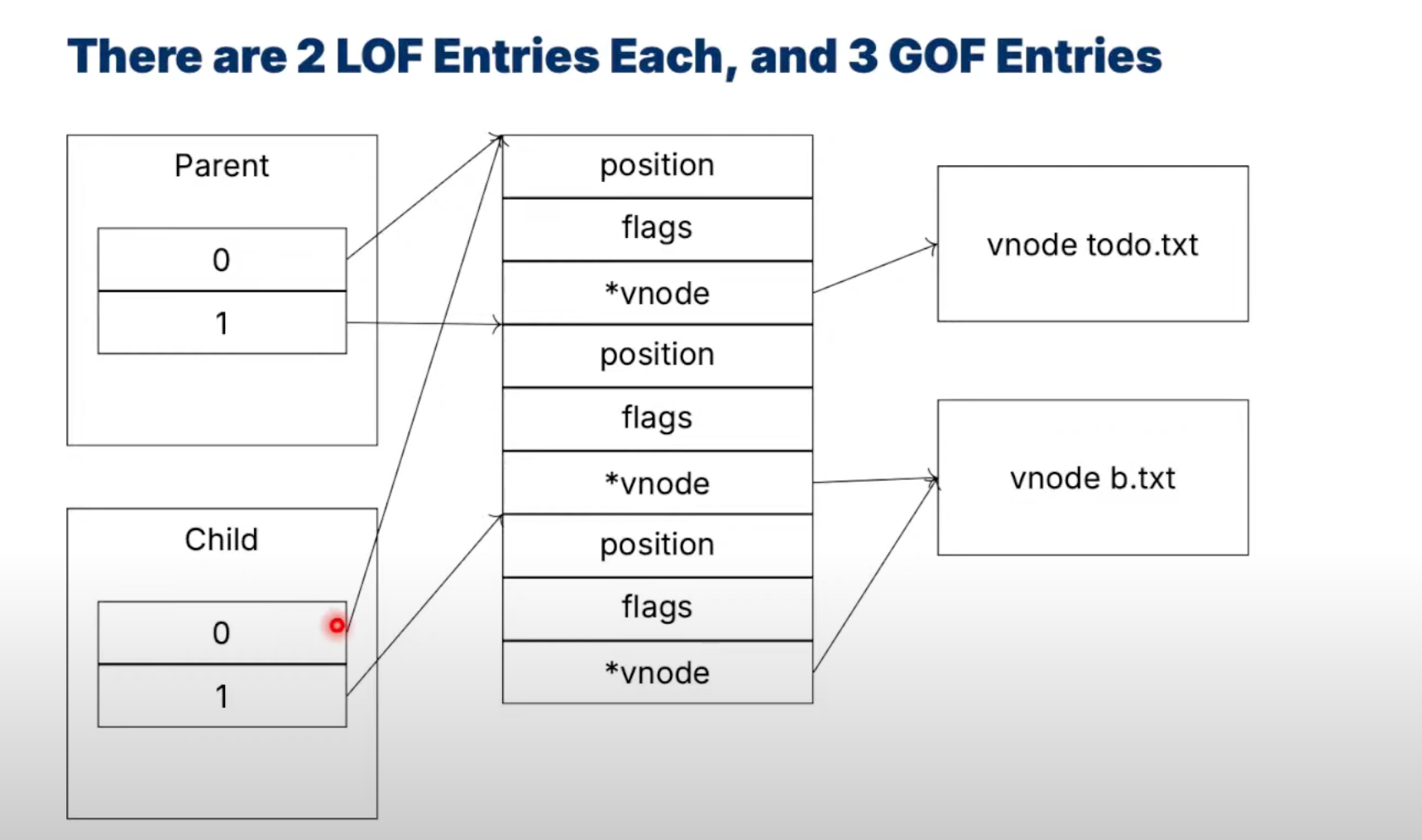
-
void read_file(int fd) {
char buffer[4096] = {0};
ssize_t bytes_read = read(fd, buffer, sizeof(buffer)-1);
printf("pid %d read %d bytes: %s\n", getpid(), bytes_read, buffer);
}
int main(void) {
int fd1 = open("a.txt", O_RDONLY);
fork();
int fd2 = open("b.txt", O_RDONLY);
read_file(fd1);
read_file(fd2);
return 0;
}it outputs:
pid 415 read 8 bytes: hello a
pid 416 read 0 bytes:
pid 416 read 8 bytes: hello b
pid 415 read 8 bytes: hello b -
store files -- file allocation table (FAT)
- fast random access, but FAT would be linear
- how to increase random access spead -- use multi-level indexed allocation maps
Indexed Nodes
-
inodes: how the kernel represents a file in the file system (basically a big C structure with a whole bunch of things on it)
-
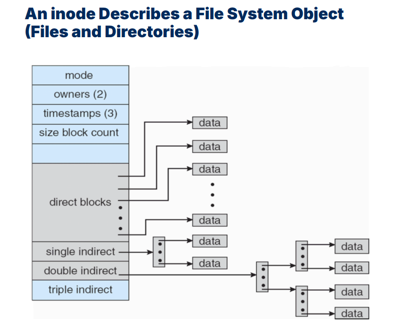
-
A directory entry (aka filename) is called a hard link, which is a pointer that points to one inode
- multiple hard links can point to the same inode
- deleting a file only removes a hard link, POSIX has the
unlinkcall rather than adeletecall
-
Soft Links Are Paths to Another File
-

-
touch todo.txt
ln todo.txt b.txt
ln -s todo.txt c.txt
mv todo.txt d.txt
rm b.txt

-
-
In unix, everything is a file
- Directories are files of type “directory”
- Additional types are: “regular file”, “block device”, HDDs, SSDs), “pipe”, “socket” etc.
- Directory inodes do not store pointers to data blocks but rather filenames and pointers to inodes
-
what data is stored in an inode
- Filename
- Containing Directory name
- File Size
- File type
- # of soft links to file
- location of soft links
- # of hard links to file
- location of hard links
- access rights
- timestamps
- file contents
- ordered list of data blocks
-
Filesystem Caches Speed Up Writing to Disks
-
File blocks are cached in main memory in the filesystem cache
-
Referenced blocks are likely to be referenced again (temporal locality)
-
Logically near blocks are likely to be referenced (spatial locality)
-
-
A kernel thread (or daemon) writes changes periodically to disk
-
flushandsyncsystem calls trigger a permanent write
-
-
Journaling Filesystem
-
Deleting a file on a Unix file system involves three steps
- Removing its directory entry.
- Releasing the inode to the pool of free inodes.
- Returning all disk blocks to the pool of free disk blocks.
-
Crashes could occur between any steps, leading to a storage leak
-
The journal contains operations in progress, so if a crash occurs we can recover
-
-
Everything is a file on UNIX, names in a directory can be hard or soft links
-
inodes are offer greater flexibility over: contiguous, linked, FAT, or indexed